Meet your users where they are
Hello 👋
In this week’s newsletter I talk about the importance of meeting your users where they are.
There’s also links to articles on a meshy approach to building data models, SQL patterns for catching fraud, and the case for data marketplaces.
Meet your users where they are
Around 8 years ago, before we built a self-serve data platform around the concept of data contracts, we built this capability we called the Data Platform Gateway.
It had many of the same goals we later met with data contracts. We wanted to enable software engineers to publish their own data, matching their own schemas, and easily make that available to their consumers, without needing to involve the data team each time.
If successful, this would have brought data producers and consumers closer together, improving the quality and applicability of data being published, and removed ourselves from being a bottleneck for all data use.
The architecture was fairly straightforward. We allowed software engineers to provide a schema in Apache Avro by uploading it to a git repo. From there it was automatically deployed to an API endpoint, so it could accept and validate the incoming data, and a table was provisioned in our data warehouse (in our case BigQuery), so the API could write it somewhere.
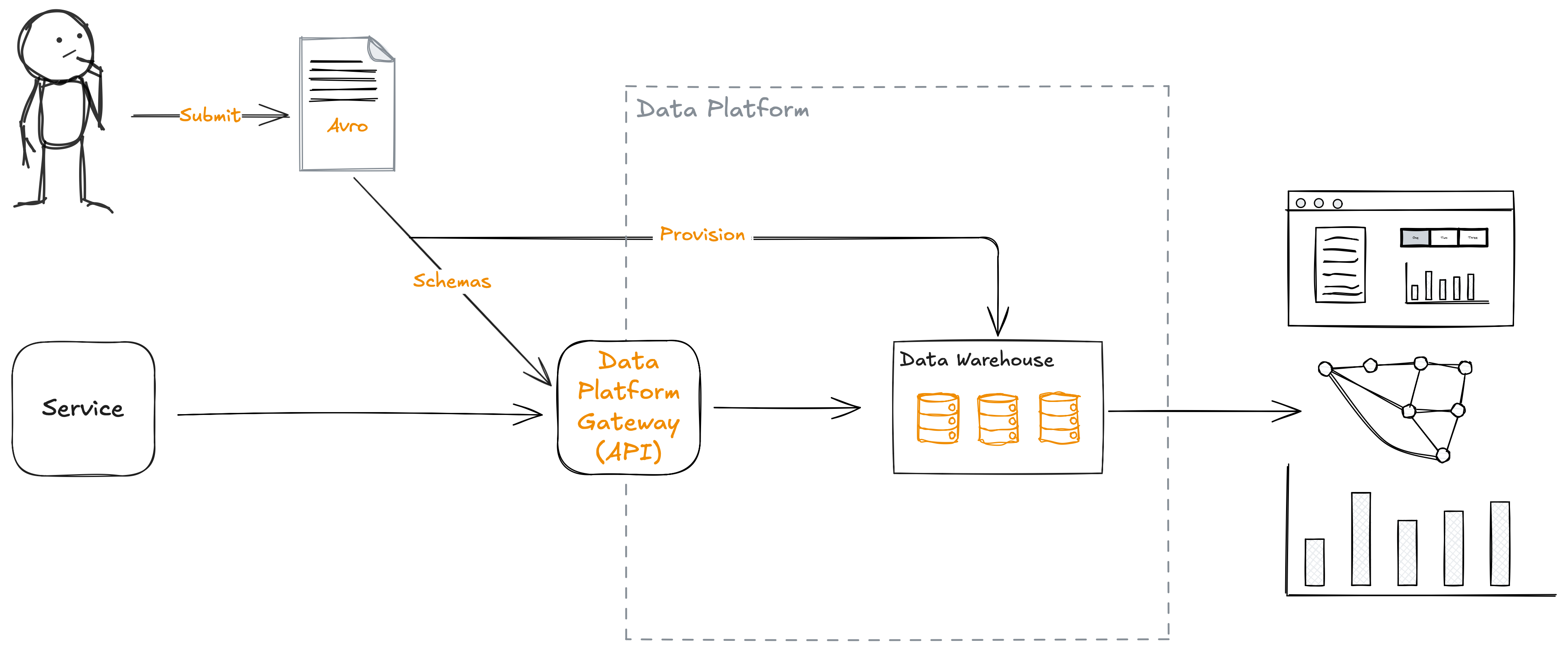
This worked fairly well, and we had dozens of schemas deployed. But one of the issues we found was our choice of using Avro.
Our software engineers didn’t like Avro.
Well, it’s not that they didn’t like it, it’s more they didn’t know it. So, every time they wanted to create a new schema, or make a change to an existing schema, they had to learn how to use Avro, how to do the weird union stuff, find out how things are deployed and how to debug issues, and so on.
Worse still, it didn’t work well with their stack…
We chose Avro because we knew it well, used it in a few places already, and knew it would work well in our stack (JVM and Python).
But, our engineers were using Ruby, and it turns out the Avro libraries for Ruby are not so good and repeatedly caused us problems.
The key learning is that we were not meeting our users where they are.
Instead, we were asking them to meet us where we were, using our favourite tools.
That meant their developer experience was poor, with too much friction, and that limited the uptake we could achieve with this solution.
We got this right when we built our next data platform on data contracts.
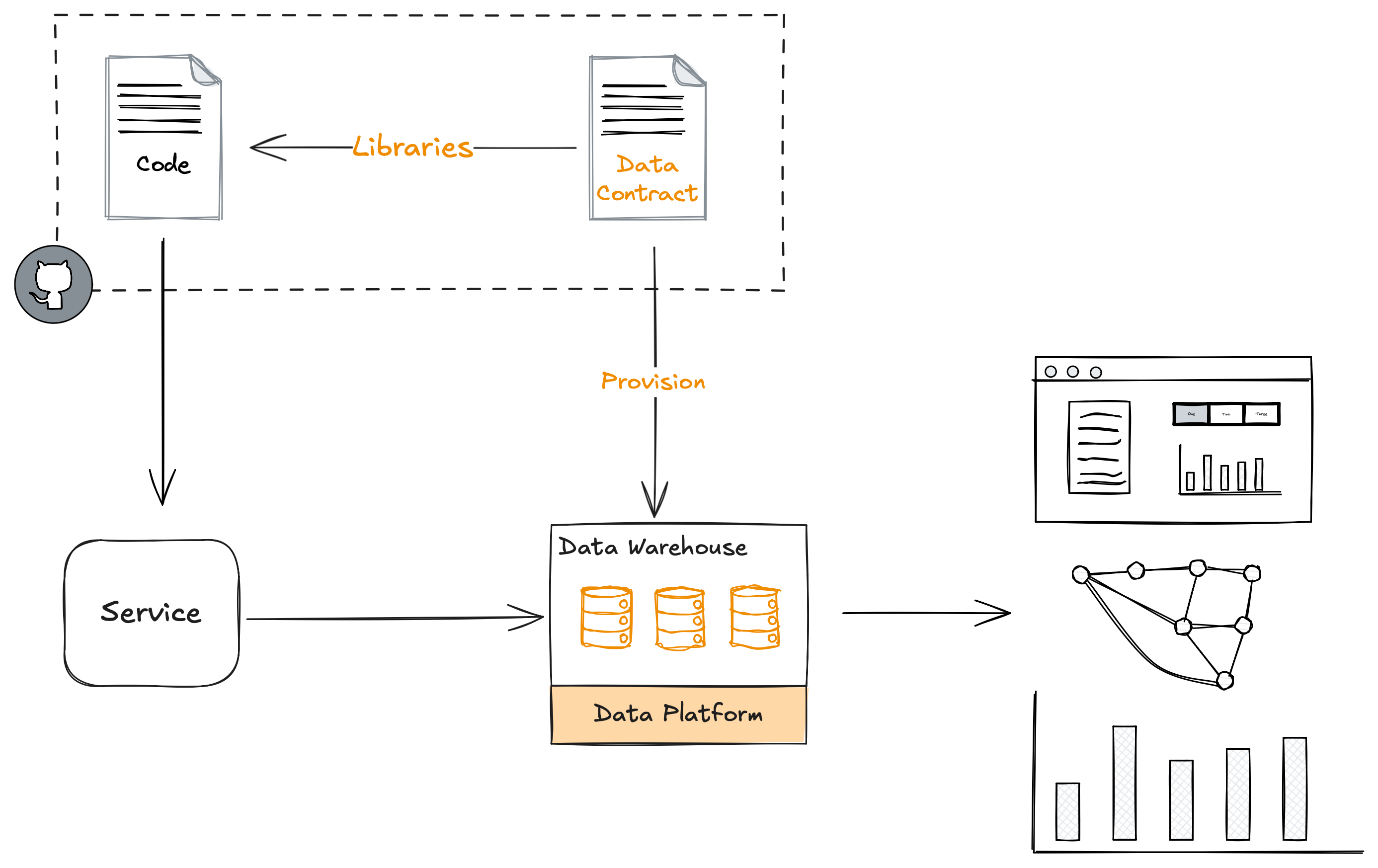
This time we really thought about the developer experience of our software engineers and meeting them where they are.
The contracts themselves were in their git repo, not ours, and rather than have them write Avro we allowed them to define their data contracts in Jsonnet, which is a configuration language based on JSON. We chose that not because it’s the best language to use for data contracts (it’s probably not!), but because they were already familiar with Jsonnet, using it to define infrastructure as code and other config, so they were comfortable with it and knew how to debug any issues with it, using tooling they already knew, which greatly reduced the barrier to adoption.
This focus on their developer experience and commitment to meeting them where they are helped ensure this platform was a success, with 200+ data contracts being deployed over the course of a few years.
There are a few other things we got wrong in the Data Platform Gateway and got right later in data contracts. I cover those in the talk I’m doing at the moment, next up at Data Mesh Live next week, and in my book.
Interesting links
A “meshy” approach to Data: Enabling 100+ teams to build Data Models by Antonia Badarau, Irina Mugford, and Massimo Frangiamore (Monzo)
Really good post on their approach to federation and automation.
And of course, it starts at the source:
This was only possible because of how Monzo’s data ingestion from the backend is designed: our microservices emit events in a consistent, well-structured format.
Six SQL patterns I use to catch transaction fraud by Fixel Smith
Nice pattens for fraud detection/anomaly detection.
BARC Spotlight: A Data Marketplace Is What Your Agents Need by Entropy Data
Interesting report, and certainly we do need to find a way to give both humans and agents more context.
Being punny 😅
My mate lost his job as a pole vaulter. Never got over it.
Upcoming events
- Data Mesh Live, next week, Belgium
- Use this link for a 15% discount
- Also join me for my Implementing a Data Mesh with Data Contracts
- Data Community Conference, September, London
Thanks! If you’d like to support my work…
Thanks for reading this weeks newsletter — always appreciated!
If you’d like to support my work consider buying my book, Driving Data Quality with Data Contracts, or if you have it already please leave a review on Amazon.
Enjoy your weekend.
Andrew