You can't just blame data producers for poor data quality
Hello again 👋
In this week’s newsletter I write about how we can’t just blame data producers, we need to look at ourselves and the support we give them.
There’s also links to context, finally achieving self-serve analytics, and synthetic customers. Enjoy!
You can’t just blame data producers for poor data quality
As data teams we know what poor quality data looks like. We see it all the time from our upstream data producers!
Many of us ask questions like “why can’t they just create better quality data - it’s not that hard!”. (Rhetorically of course, and not to their faces.)
But while it’s easy to blame them, we also need to look at ourselves, and how we are supporting them.
Because creating good quality data isn’t easy. In fact, it’s hard to agree what good quality data even looks like.
And someone who is a software engineer with their own problems to solve and deadlines to meet doesn’t want to and isn’t able to spend the time to understand what good quality data is.
For example, let’s say a software engineer is rolling out a new feature, and as a data team you want good quality data on usage of that feature so you can create reports showing the ROI of that feature, how it impacts upselling, and so on. That software engineer isn’t likely to know what good data looks like here, and by leaving the expectation on them to work it out, you’ll see them put that task to the bottom of their list, deferring it to later, until later becomes never.
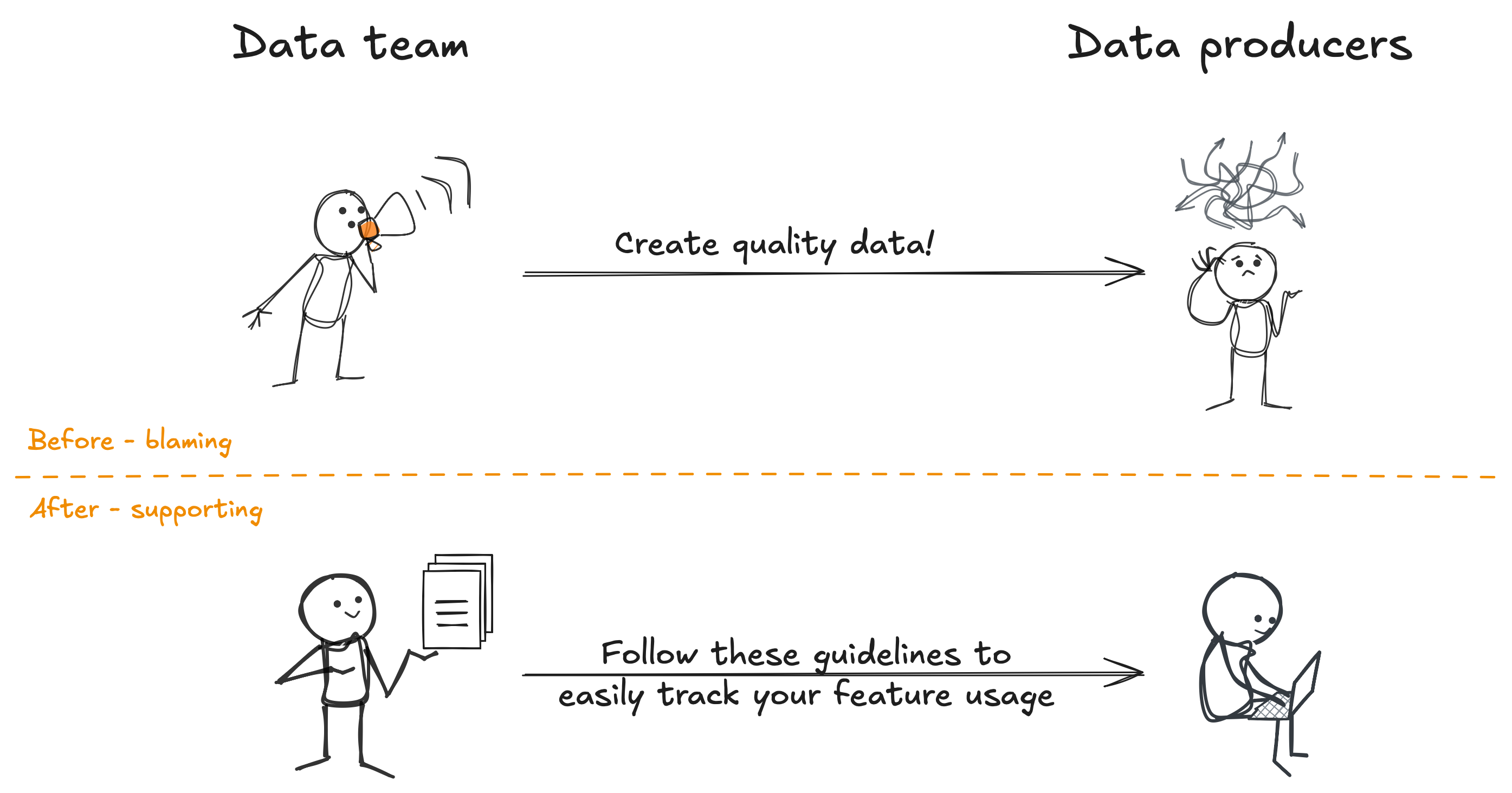
Instead, we should be providing them with the support, guidance, and tools to reduce their cognitive load, allowing them to follow simple steps to publish good quality usage data.
That could include:
- How to link usage to a user, including which ID to use
- Clear guidelines for how feature usage must be measured
- Libraries for collecting usage data, which include local validation they can use in their own test suites
- Examples of other usage data, including data schemas, sample code, etc
- Agent skills that help them design usage data for their particular feature
And so on.
Given support like this, at exactly the time they need it, a software engineer now has everything they need to easily collect and publish good quality usage data that you as the data team can depend on.
Interesting links
The Data Context Trap by Duncan Gilchrist and Jeremy Hermann (Delphina)
A good framing of the difficulties building a “context layer”, albeit through the lens of their solution.
Related to the above link, maybe this is finally the time we truly achieve self-service analytics.
Synthetic Customers Earn Their Stripes by Andy Pierce, Laura Beaudin, Nitin Gupta, Vinoth Rajasekar, Colleen Lin, Basma Abdel Motaal, and Hamish Nairn (Bain & Company)
Really interesting use of synthetic data to create “synthetic customers” for user research.
Being punny 😅
Last weekend, I competed in the world race walking championship for the fourth time running. Needless to say, I was disqualified.
Upcoming events
- Data Mesh Live, June, Belgium
- Use this link for a 15% discount
- Also join me for my Implementing a Data Mesh with Data Contracts
- Data Community Conference, September, London
Thanks! If you’d like to support my work…
Thanks for reading this weeks newsletter — always appreciated!
If you’d like to support my work consider buying my book, Driving Data Quality with Data Contracts, or if you have it already please leave a review on Amazon.
🆕 I’ll be running my in-person workshop, Implementing a Data Mesh with Data Contracts, in June in Belgium. It will likely be only in-person workshop this year. Do join us!
Enjoy your weekend.
Andrew