Integration vs Interoperability
Hello 👋
This week I’m writing/thinking out loud about integration vs interoperability, and whether we really need to centralise everything in a data warehouse before we can make use of data.
There’s also links to articles on the foundation for context graphs, operationalising data science, and small data.
Integration vs Interoperability
In any organisation of size there will be many datasets in many systems related to the same entity, and there would be value in being able to join that data together to provide a more complete view of that identity.
This is often the reason for starting a new project to create a data pipeline that replicates data from these different sources into a central location, e.g. a data warehouse, so the data can be easily joined.
Often they are given a name like ENTITY 360, with the outcome that all the data about this entity will be available in this one location.
Unfortunately, these data replication projects tend to be expensive, and the data pipelines that are implemented tend to be brittle.
Which leaves you having to hire a number of data engineers who do nothing but this work, and who can never keep up with the work needed, leading to them becoming a bottleneck for further integrations.
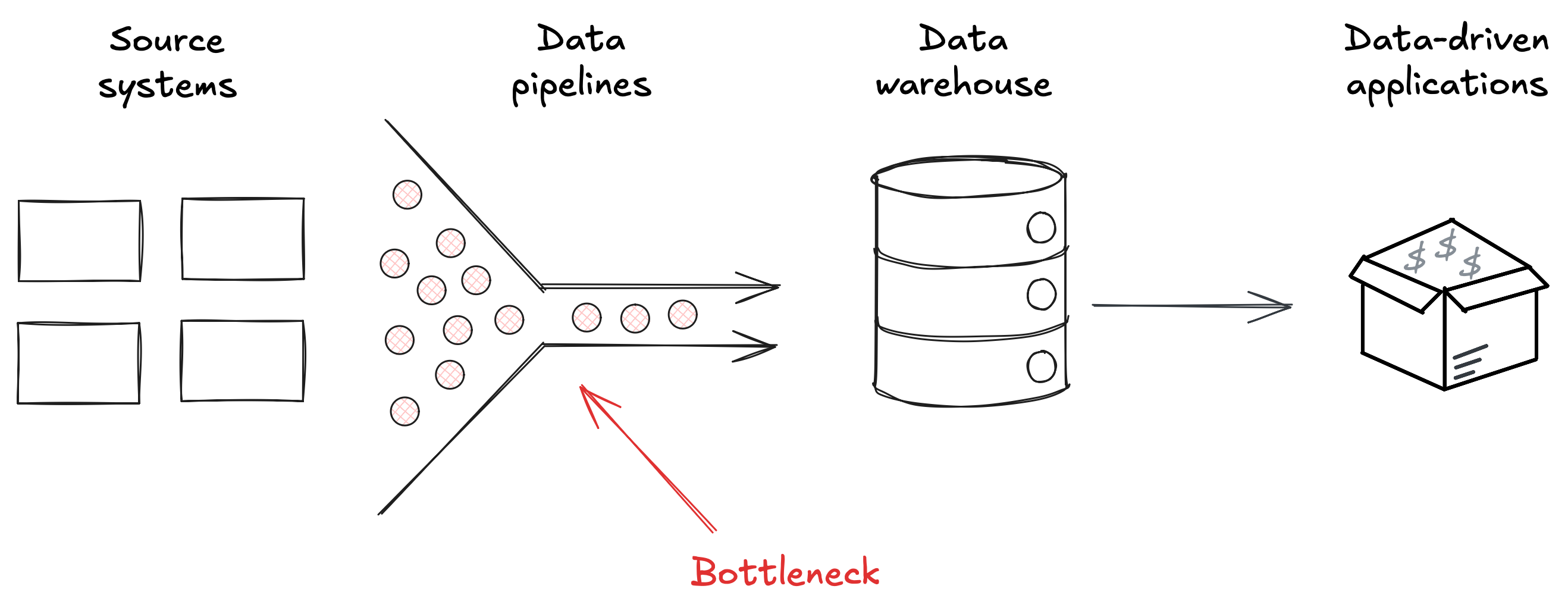
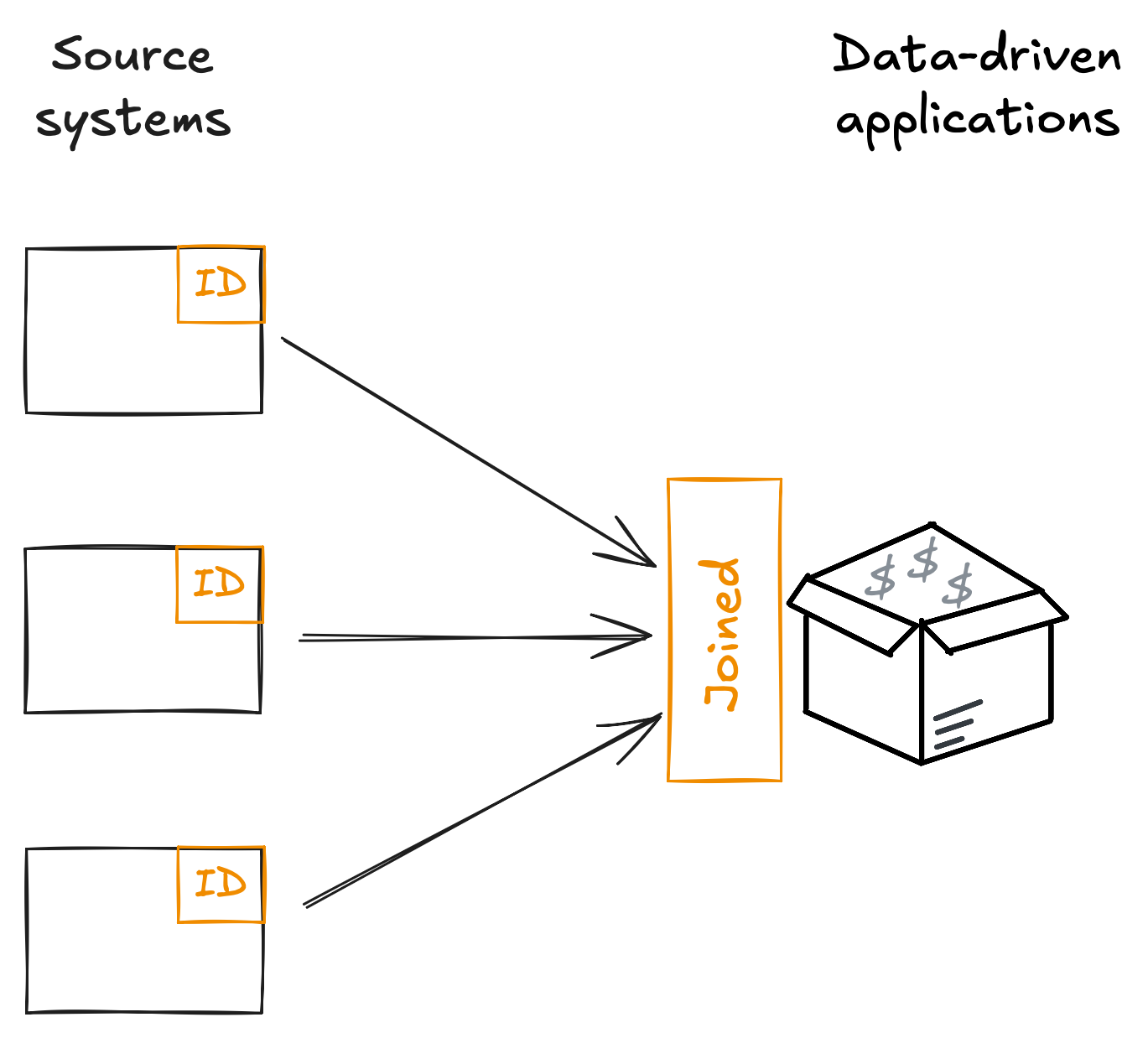
An alternative strategy is to accept there will always be many systems that create data about these entities, and instead invest in how they can be interoperable, so when you have a use case that requires x from one system and y from another you know they can be joined and made available to that use case, right where it needs it.
To achieve this level of interoperability we need to have agreement across systems which IDs to use, and ensure those IDs are present and correct in each of those systems.
Once we have that agreement, we need to make it easy for the different systems to assign those IDs, and monitor the completeness and accuracy of those IDs in those systems.
There are a few ways to do this, and a while ago I spoke to a team using data contracts for this.
They ensured that whenever the field was listed in the data contract, it was clear this was a particular ID, and all the documentation, the semantics, the quality checks, and so on were applied to that field.
They also provided libraries that the systems could use to easily do lookups and assignment of IDs, making it as easy as possible to adopt the use of this ID in their system and ensuring the accuracy of the IDs being used.
Through this work they were able to move away from the assumption that all data needed to be centralised before being usable, reducing the amount of data pipeline work, and removing themselves as a bottleneck.
That freed them up to provide this tooling to the business, and focus on delivering the data for the use cases to consume where they needed to consume it.
Now, I’m not one for hyperbolic statements like “the warehouse is dead”, but I do think it’s worth challenging the assumption that a warehouse is needed before we can join and make use of data.
And we have more tools and patterns available to use today that help us implement alternatives to the data warehouse.
Interesting links
Why Lineage and Quality Metrics Are the Foundation of Context Graphs by Eric Simon
Turns out it’s all about metadata.
Data Science Is Easy. Operating It Is Not. by Storm King Analytics
This is another example of why you need interfaces between boundaries, in this case between data science datasets and analytics/low code systems.
It’s the same lesson that led to APIs, the same lesson that led to data contracts.
A Small Data Manifesto by Hodman Murad
Most of us are only dealing with small data and relatively simple requirements, so why use complex tools?
Being punny 😅
I drove a long way in winter weather to get parts to fix my computer. It was a hard drive.
Thanks! If you’d like to support my work…
Thanks for reading this weeks newsletter — always appreciated!
If you’d like to support my work consider buying my book, Driving Data Quality with Data Contracts, or if you have it already please leave a review on Amazon.
🆕 I’ll be running my in-person workshop, Implementing a Data Mesh with Data Contracts, in June in Belgium. It will likely be only in-person workshop this year. Do join us!
Enjoy your weekend.
Andrew