Reversing Conway's law
Hello 👋 hope you had good week!
Once again I’ll be running my in-person workshop, Implementing a Data Mesh with Data Contracts, in June in Belgium alongside Data Mesh Live. It will likely be the only in-person workshop I run this year. Do join us if you can! Hit reply if you have any questions :)
Now, on to the newsletter, and today I’m writing about reversing Conway’s law to make it work for you.
There’s also links to articles on the importance of foundations, the semantic loop, and Temporal at Netflix.
Reversing Conway’s law
Conway’s law asserts that the designs of systems are influenced by an organisation’s communication structure, suggesting that how teams are organised and communicate will be reflected in the final product.
So if we apply that to data, it’s not surprising that achieving value from data is difficult when data teams are often placed in a separate part of the organisation from where the data is generated.
It makes communication between data producers and data consumers more difficult, and incentivises the data teams to work around poor data quality by building complex and expensive ETL pipelines rather than try to address the problem at the source.
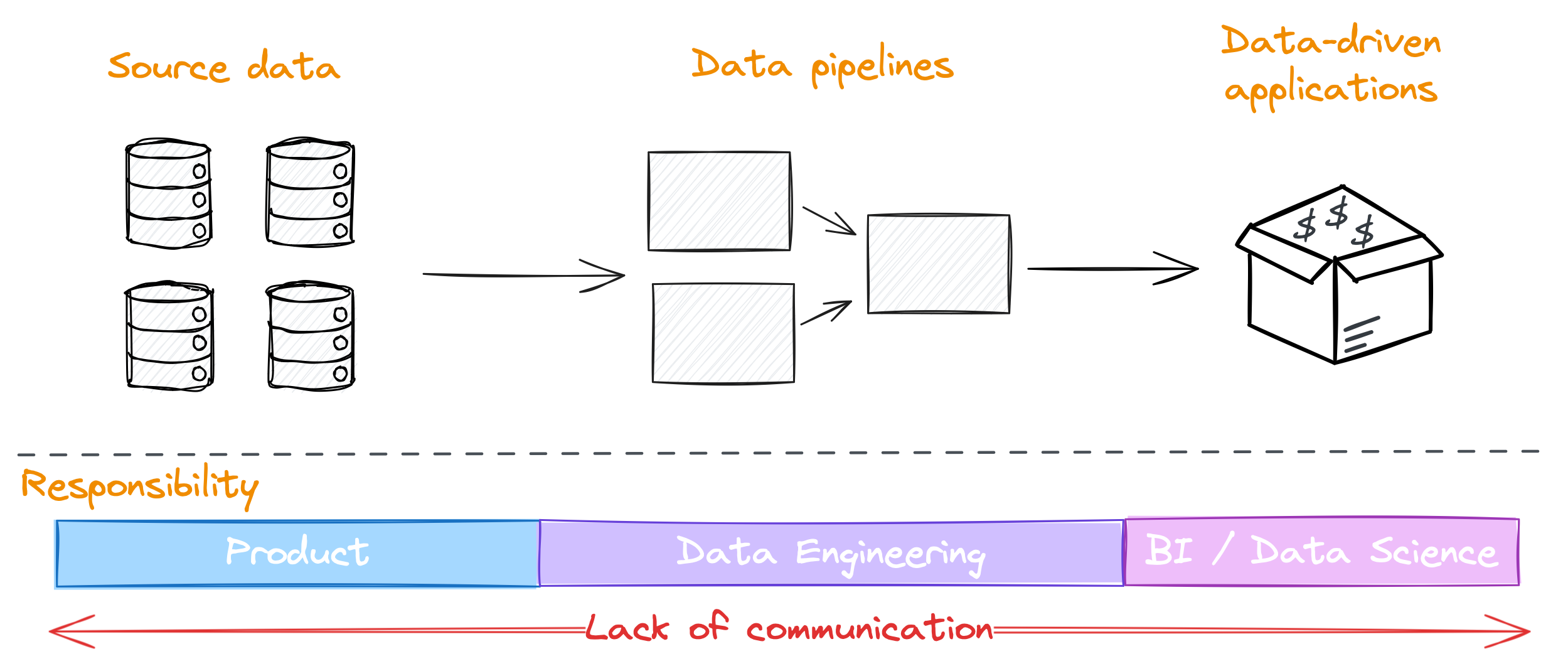
While it might be ideal to solve this problem by changing your organisational structure, that’s not always achievable.
But there are things we can do to work against Conway’s law.
One of those is to work hard to improve the communication across organisational barriers, through personal connections and utilising different communication channels like tech talks, newsletters, and so on.
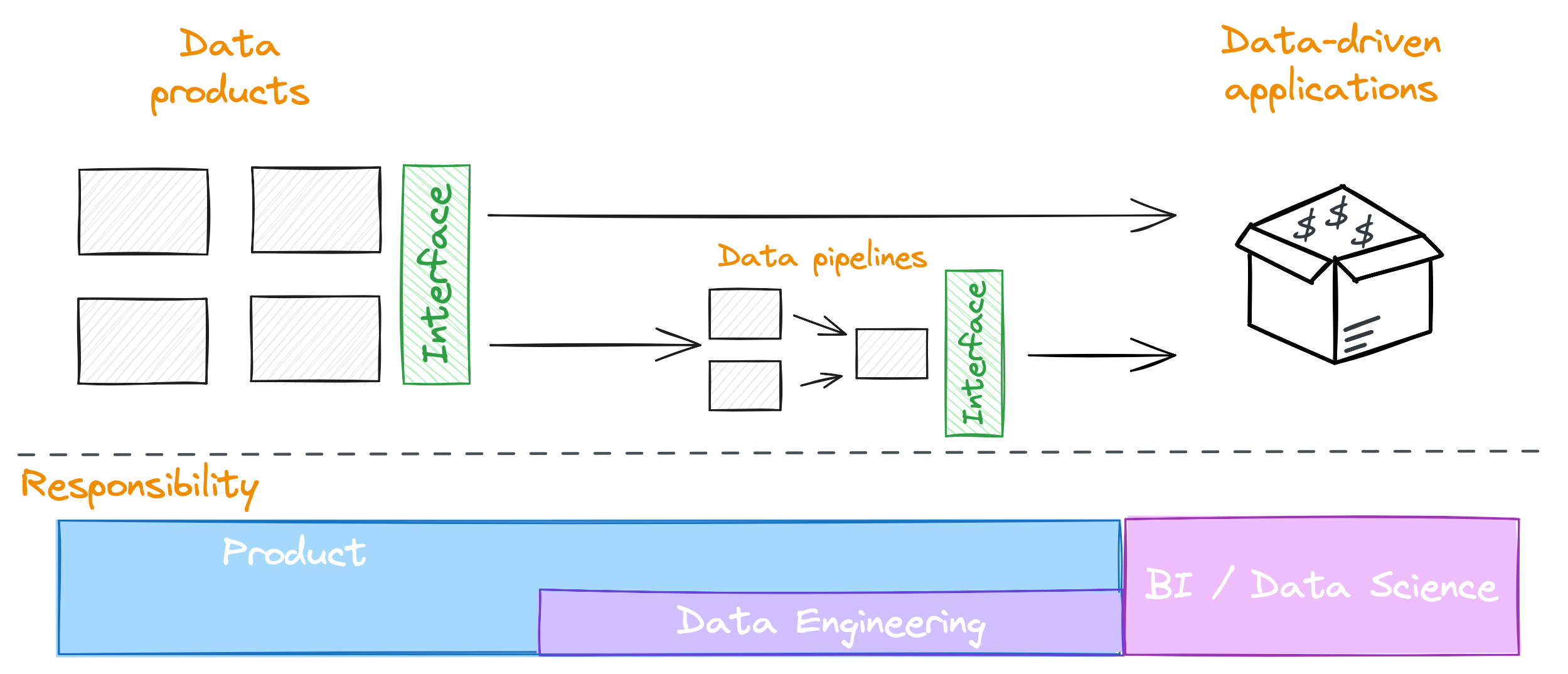
The other is to design your data architecture so that it naturally supports the communication structures you need, encouraging the organisational structure to evolve in that direction.
This is sometimes called reverse Conway’s law, which states that organisations will reorganise themselves around their architectures.
That’s something we can use to our advantage.
For example, we can design a data architecture that makes it easy for data producers to create and manage the data they own.
On the other hand, we make it harder for unmanaged data to move around the organisation (i.e. we’re deliberately adding friction).
Over time, we’ll see more data being managed by the data producers, because that’s what is easiest for them.
They may find they start having a lot of data to own and manage, which may lead to them hiring dedicated data engineers within their team/group/division to support that.
So, by taking advantage of reverse Conway’s law, we are starting to change the organisation from the bottom-up, moving to a more decentralised model of data ownership, where those who produce the data own it and are responsible for it - reducing ETL costs downstream and increasing the quality of our data.
Interesting links
It Depends by Veronika Durgin
Great article on why the foundations matter.
A good red flag to watch for: If every new feature feels harder, slower, or riskier than the previous one, you’re probably paying for capabilities you didn’t invest in earlier.
The Semantic Loop: Implementing the Circular Data Architecture by Stefan Frost
Interesting ideas on a more circular view of the data landscape
How Temporal Powers Reliable Cloud Operations at Netflix by Jacob Meyers and Rob Zienert
I’ve been keeping an eye on Temporal and similar tech for a while as I think it (or something like it) could be a game changer for data pipelines, though I haven’t yet seen it used in data platforms, and I haven’t had a chance to myself yet. If you know of any data teams using Temporal I’d love to hear about it!
Being punny 😅
I really don’t like going to arenas because it’s always SO windy in there. There’s just so many fans!
Thanks! If you’d like to support my work…
Thanks for reading this weeks newsletter — always appreciated!
If you’d like to support my work consider buying my book, Driving Data Quality with Data Contracts, or if you have it already please leave a review on Amazon.
🆕 I’ll be running my in-person workshop, Implementing a Data Mesh with Data Contracts, in June in Belgium. It will likely be only in-person workshop this year. Do join us!
Enjoy your weekend.
Andrew