Source-aligned data products, or output ports on the source?
Hello 👋
This week I write about source-aligned data products and whether they really solve the problems we had, or if instead we need a more suitable output port on the source system.
Also links to articles on scaling data platform teams, the automation paradox in data governance, and the minimalist data contract.
Source-aligned data products, or output ports on the source?
When it comes to integrating data from upstream services, source-aligned data products are really no different to how we’ve always integrated data.
Data is still extracted by centralised/separate data engineering teams who have little understanding of the source systems and how the data is modelled.
The source-aligned data products are still designed to mirror the internal data structures of the source system, using tools like CDC or ELT, creating a tight coupling to those data structures and requiring deep knowledge of the source systems to use.
The owners of the source systems still have little or no knowledge or responsibility for these source-aligned data products, which means a lack of change management, no SLOs, and poor reliability.
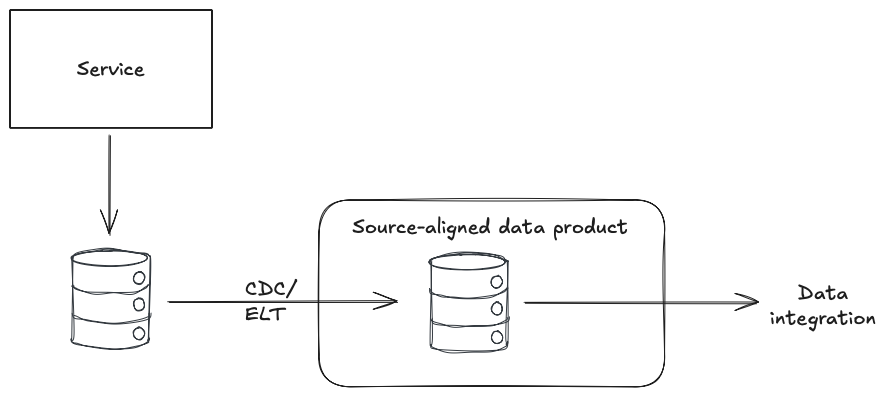
So, the same problems we had before, just renamed.
To solve these problems we need to move away from the assumption we need an extraction of data from source systems and towards the use of interfaces - or, as data mesh calls them, output ports - on the source system.
These source systems likely already provide an interface to support integrations with other systems - an API.
Many teams treat this API as a product that provides their consumers with:
- Data models designed for easy consumption, that could/will be different from the underlying database
- Loose coupling, so the source system can change without the API changing
- Change management, through API versioning and backwards compatibility
- Reliability and confidence, backed with SLOs
As the owners of the source system, they know exactly how best to build and operate this API and can take responsibility for providing and maintaining this product for their consumers.
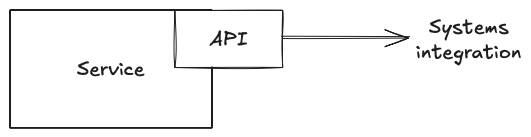
Unfortunately, we can’t easily build data integrations on these APIs, as they tend to support small amounts of data extraction and are modelled around individual records.
What we need is a different interface - a different output port - providing us with the data we need to meet our use cases.
Typically this would be an event stream and/or a regular write to the data warehouse, using a data contract for schema management.
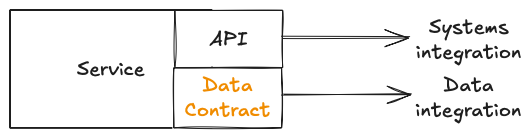
There are two reasons why source systems rarely provide this additional output port:
- Data teams have for decades assumed the responsibility for building these extractions, with all the effort and poor results that come from it, because we assumed we couldn’t ask for anything different
- The tools for systems owners to easily build these interfaces often don’t exist, and certainly are not of the same quality as the tools they have for building an API, which typically is just a bit of code for them to write with authorisation, observability, etc, provided by the platform
Solving that first problem requires a shift in mindset, and the realisation that we are creating something valuable enough to the company that we can ask for dependable inputs, just like other teams do.
The second problem requires investing in the data platform to provide the tooling that makes creating this data contract as easy as creating an API.
But if we can do those things we would make the source-aligned data products redundant, saving all that effort, avoiding all those issues, and improving the reliability and quality of our data integrations.
That’s an investment worth making.
Interesting links
Scaling Data Platform Teams: A Step-by-Step Guide by Xavier Gumara Rigol
Good advice on starting and then scaling data platform teams.
The Automation Paradox in Data Governance by Winfried Adalbert Etzel
I’m a big proponent of automating/embedding data governance, but I think it is fair to highlight that it can risk making data governance less visible. This article has some good strategies for managing that risk.
The Minimalist Data Contract by Jean-Georges Perrin
A minimal data contract using the Open Data Contract Standard.
Being punny 😅
The most disapproving of all the Pharaohs was King Tut.
Thanks! If you’d like to support my work…
Thanks for reading this weeks newsletter — always appreciated!
If you’d like to support my work consider buying my book, Driving Data Quality with Data Contracts, or if you have it already please leave a review on Amazon.
🆕 Also check out my self-paced course on Implementing Data Contracts.
Enjoy your weekend.
Andrew