The outbox pattern for publishing events
Hey, hope you’ve had a good week!
Today’s post is the second part of a mini-series on publishing events, and today I explain the outbox pattern.
There’s also links to articles on silos, integrations, and building reliable log delivery.
The outbox pattern for publishing events
As mentioned last week, with data contracts we want to move to a model where data and events are published to consumers, rather than replicated from databases. That requires adopting new patterns and providing the tooling that enables them.
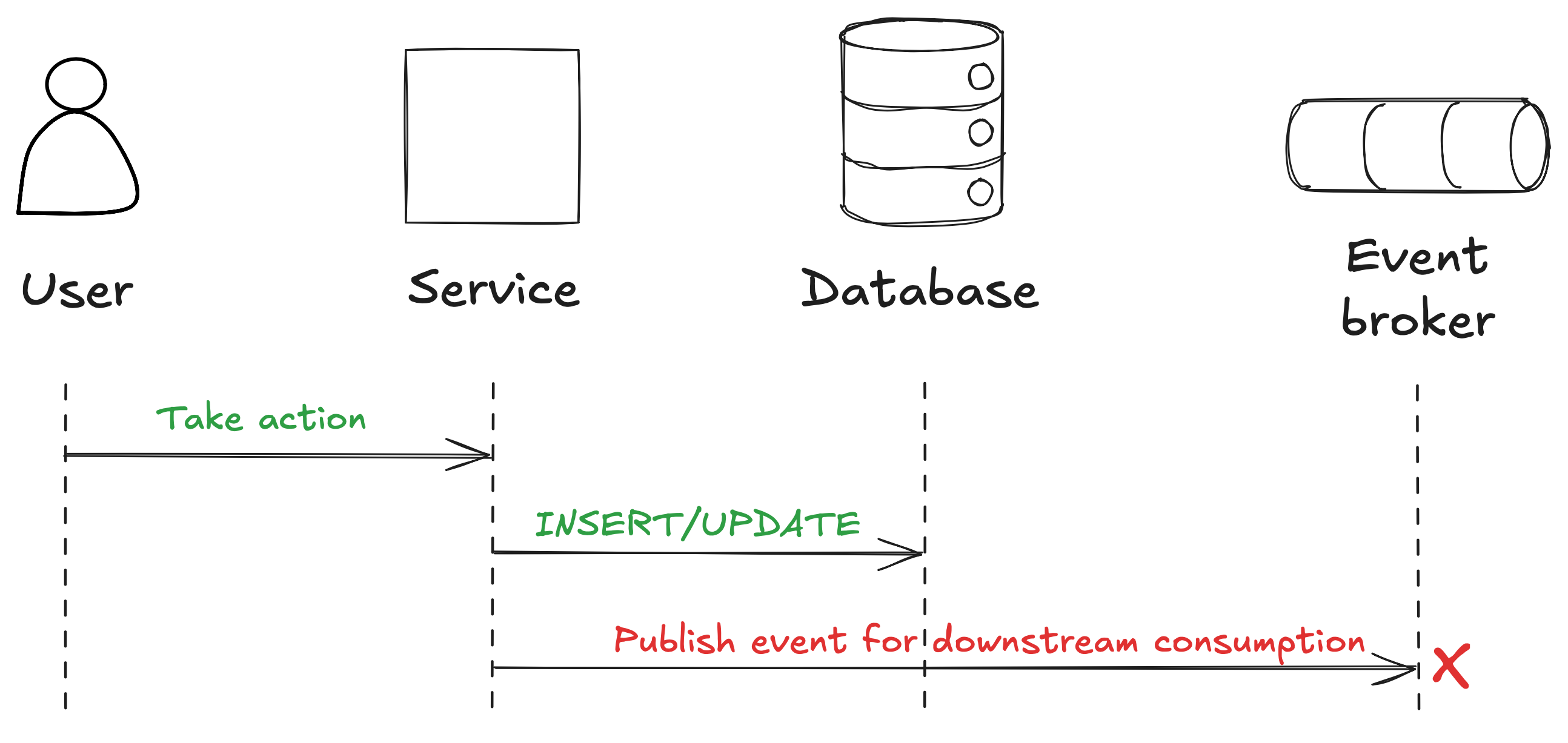
Last week we looked at the simplest pattern, where you just write events to an event broker after you write to the database. However, that pattern has one major drawback, and that’s known as the dual-write problem.
This happens when you have a system that needs to update two different places, in our case the database and the event broker. Logically, that should be one operation, but in this case it will be two operations, as shown below. If one fails, such as the write to the event broker, then data in those two systems will be inconsistent.
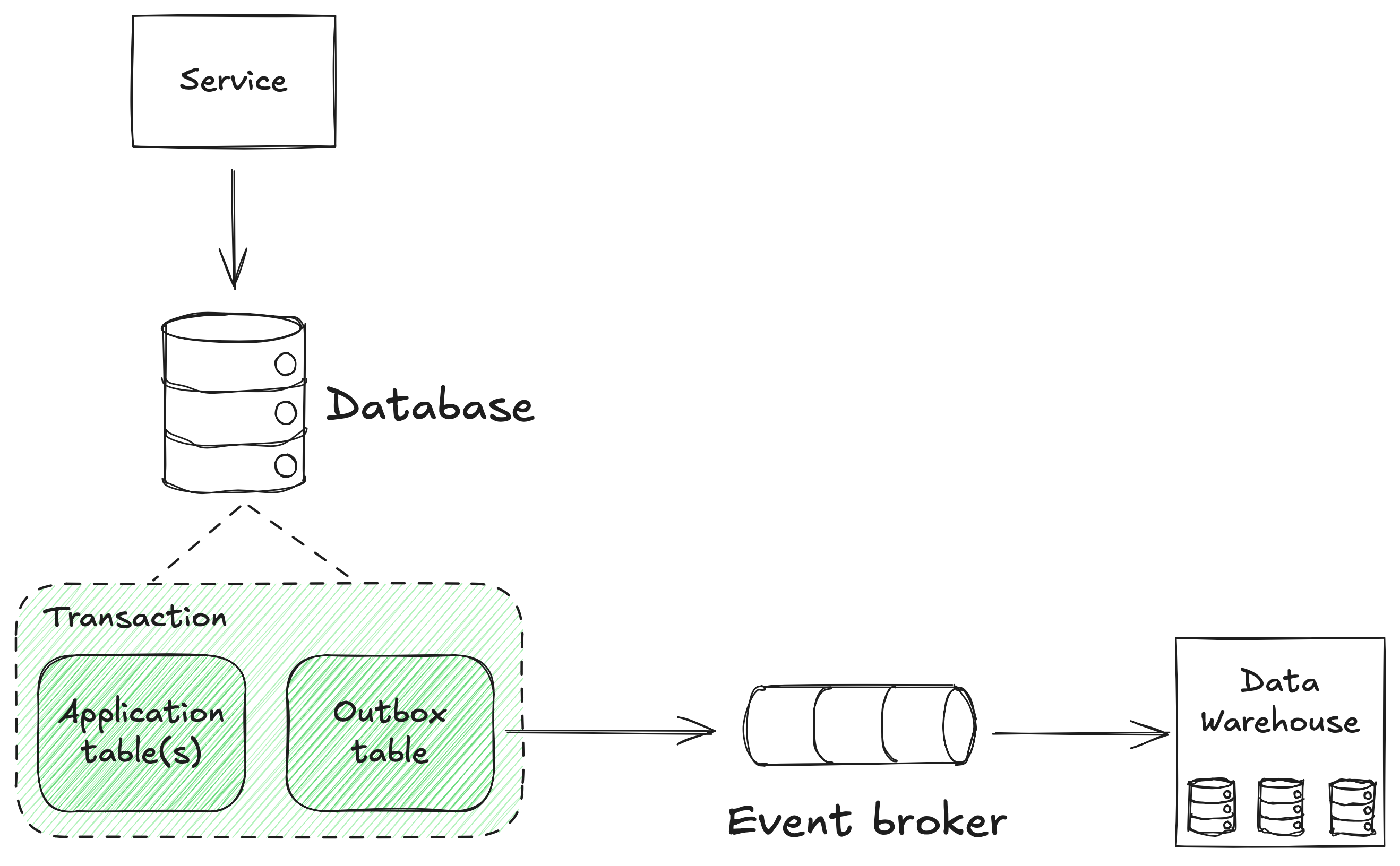
The outbox pattern is designed to solve this problem.
It does this by storing the event in the same database transaction as the business change, as a single operation, with the event written to an outbox table.
The SQL for this write would look something like this:
BEGIN;
UPDATE orders
SET status = 'PAID'
WHERE order_id = 123;
INSERT INTO outbox_events (id, type, payload, created_at)
VALUES (uuid(), 'OrderPaid', '{"orderId":123}', now());
COMMIT;
Now, if either of those writes fail, the transaction is rolled back and no data will be written.
If they both succeed, the event will be processed asynchronously by a service that reads the outbox tables and publishes them to the broker. When successfully written to the broker the record in the outbox table is deleted.
In this example the payload is just arbitrary JSON, which could still be invalid, but it could be more structured, and/or validation can be done in code as the event is generated.
This ensures strong data consistency between the database and the event broker, as well as being resilient to any issues writing to the broker.
However, it does add some complexity. It can also impact performance of the database, particularly if there are high volumes of events being generated. Most relational databases are not optimised for high-churning tables such as the outbox tables.
There is an alternative pattern that alleviates some of these drawbacks called the listen to yourself pattern. I’ll explain what that is next week.
Sponsor
Web scraping used to be such a pain. I remember writing Perl scripts to scrape the web back in the early 2010s, and they would take ages to build, only to break as soon as the site changes.
(You can still see examples of these scripts I created for my personal use on the CPAN (Perl’s version of PyPI), including scraping the Arsenal FC ticket website so I knew when tickets were released!)
Luckily, the industry has moved on, with resilient, compliant, and performant web scrapers available.
Of course, that now includes the use of AI, which completely automates the entire web scraping pipeline!
This year I’m attending the OxyCon, a FREE virtual conference, to join the community and learn the latest in web scraping and:
- How to build a scalable e-commerce scraping strategy;
- How feedback loops can be established to improve AI models with scraped data;
- How to structure messy scraped data efficiently with an API (live demo);
- How to build a price comparison tool with AI studio.
Come join me on October 1st! Sign up here.
Interesting links
Are Silos Always a Bad Thing? by Joe Reis
I like this take on silos. They are inevitable, so it’s about working with them.
Why ‘API Gateway’ is Not an Integration Style by Daniel Kocot
Not strictly an article on data, but you will recognise many of the arguments being made here as data is also largely an integration problem.
How we built reliable log delivery to thousands of unpredictable endpoints by Gabriel Reid at Datadog
Interesting apprach to building a log delivery system.
Being punny 😅
The contractor who recently finished remodelling my kitchen has been charged with counterfitting.
Thanks! If you’d like to support my work…
Thanks for reading this weeks newsletter — always appreciated!
If you’d like to support my work consider buying my book, Driving Data Quality with Data Contracts, or if you have it already please leave a review on Amazon.
Enjoy your weekend.
Andrew