Patterns for publishing events
Happy Friday!
This week is the start of a mini-series on publishing events.
Also links on unlearning data architecture, a simple data governance framework, and AI for data engineers.
Finally, on Wednesday (20th August) I’ll be live on Loosely Coupled comparing Data Mesh and Application Integration with Karol Skrzymowski and Rachel Barton. Should be fun - join us on LinkedIn or YouTube!
Patterns for publishing events
With data contracts we want to move to a model where data and events are published to consumers, rather than replicated from databases. That requires adopting new patterns and providing the tooling that enables them.
Over the next few weeks I’m going to share three patterns to publish events from services, starting today with the most simple, which is simply publishing events to an event broker.
This is really as simple as it sounds. When your service writes to a database, also send an event to the event broker.
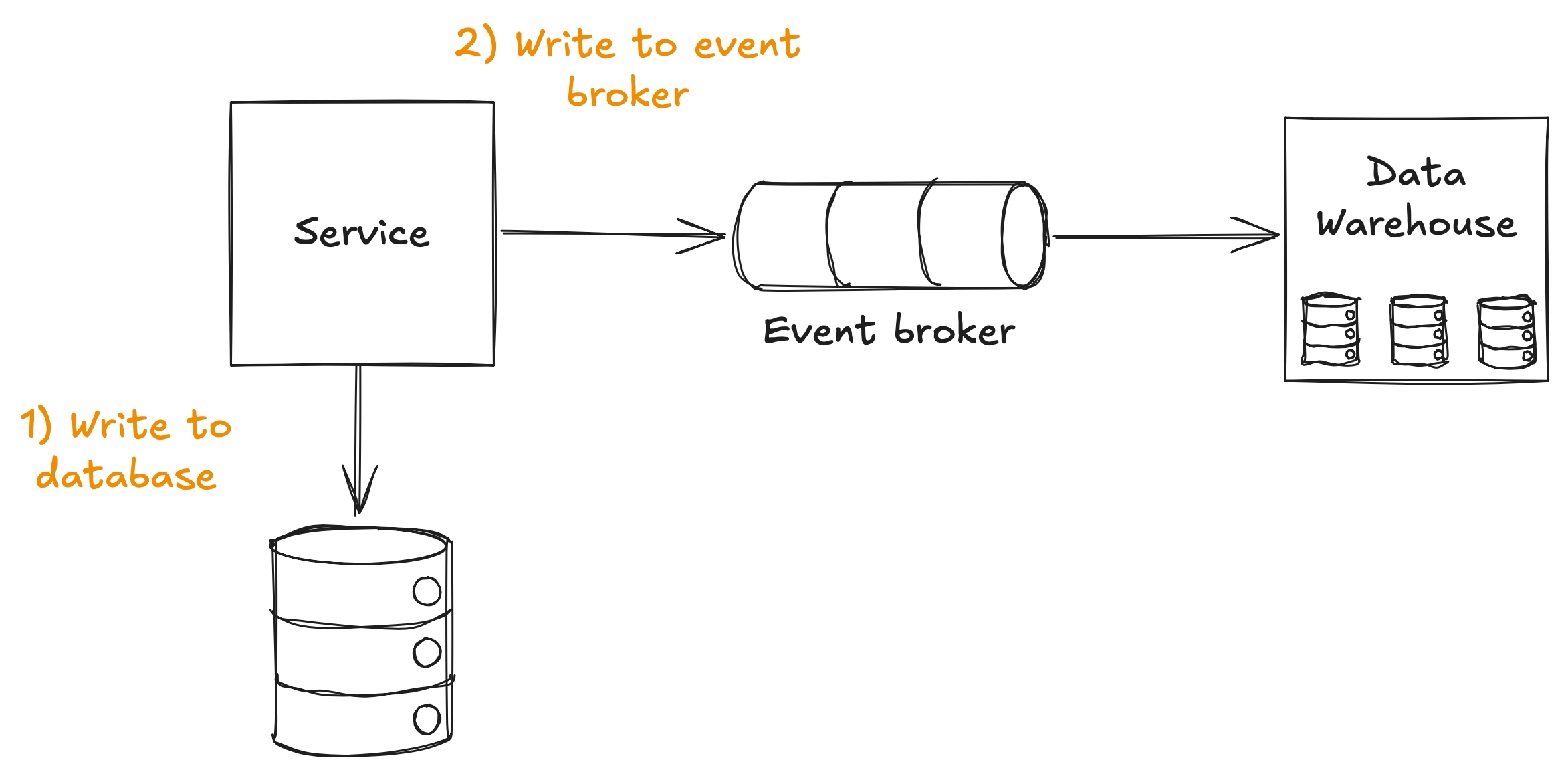
We use an event broker, such as Kafka, Google Cloud Pub/Sub, Amazon SNS, etc, because writing to it is easy and quick. We then pull events from the broker to populate our data warehouse.
While simple, performant, and easy to implement, this pattern has one major drawback, and that’s known as the dual-write problem.
This happens when you have a system that needs to update two different places, in our case the database and the event broker. Logically, that should be one operation, but in this case it will be two operations, as shown below. If one fails, such as the write to the event broker, then data in those two systems will be inconsistent.
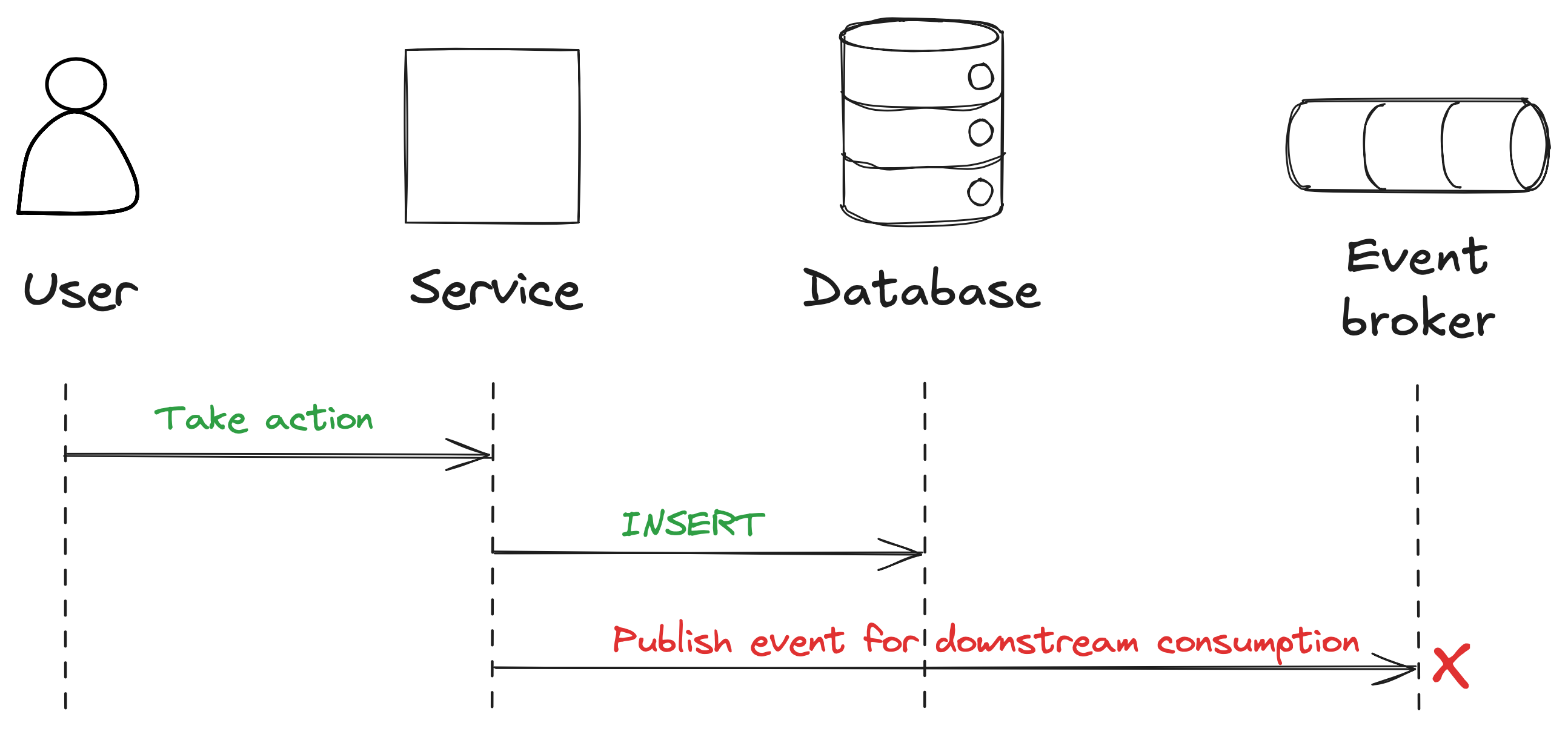
Because there’s no single atomic transaction covering both systems, one write can succeed while the other fails, leaving the systems out of sync and our data inconsistent.
That data consistency might be ok for your use case, and you would rather have slightly inconsistent data than introduce more complexity and potential performance issues into your architecture.
However, it might be that you need more consistent data than you can achieve with this pattern, and for that we need to use a more complex pattern.
I’ll be discussing two of these patterns over the next two weeks, starting with the outbox pattern next week.
Interesting links
Unlearning Data Architecture: 10 Myths Worth Killing Bernd Wessely (or via Freedium)
It’s always good to challenge assumptions, and this article is a great list of things we should reconsider.
Why do we Need a Simple Data Governance Framework? by Nicola Askham
Data governance doesn’t need to be complicated. KISS.
AI for data engineers with Simon Willison (podcast)
Good discussion on many topics, including LLMs for data extraction, MCP security, and Postgres permissions.
Being punny 😅
I accidentally drank a bottle of invisible ink. Now I’m in hospital, waiting to be seen
Thanks! If you’d like to support my work…
Thanks for reading this weeks newsletter — always appreciated!
If you’d like to support my work consider buying my book, Driving Data Quality with Data Contracts, or if you have it already please leave a review on Amazon.
Enjoy your weekend.
Andrew