How our software engineers used data lineage
Hello 👋
Today I write about how our software engineers used data lineage.
There’s also links to articles on comparing data on deploy, alignment in the age of autonomy, and reducing warehouse costs.
How our software engineers used data lineage
Data lineage is the process of tracking the movement and usage of data through an organisation. Often this tracking information is populated by looking at real-world usage, for example logs from the data warehouse, to create an accurate lineage/dependency graph.
Data lineage becomes increasingly useful in a decentralised or data mesh architecture, where data produced by one part of the organisation may be consumed by many others in different parts of the organisation, as opposed to centralised data functions who assume ownership and responsibility for all data movement.
It’s also useful when you’ve shifted ownership and responsibility left, to the data producers, including to software engineers.
And that’s what we found.
Our data contracts tooling made it easy for software engineers to publish data from their service to the data warehouse.
Within the data warehouse each service would have its own area, and that area would be owned by the same team that owned the service.
As we were using BigQuery, practically this was implemented by having a GCP project associated with the project (which we already did for all projects anyway), and putting those tables in BigQuery tables owned by that project. You can think of the GCP project as a namespace that assigns ownership, allows setting permissions, etc, but has no impact on querying the data from other projects.
These tables became the interface through which data was made available to data consumers.
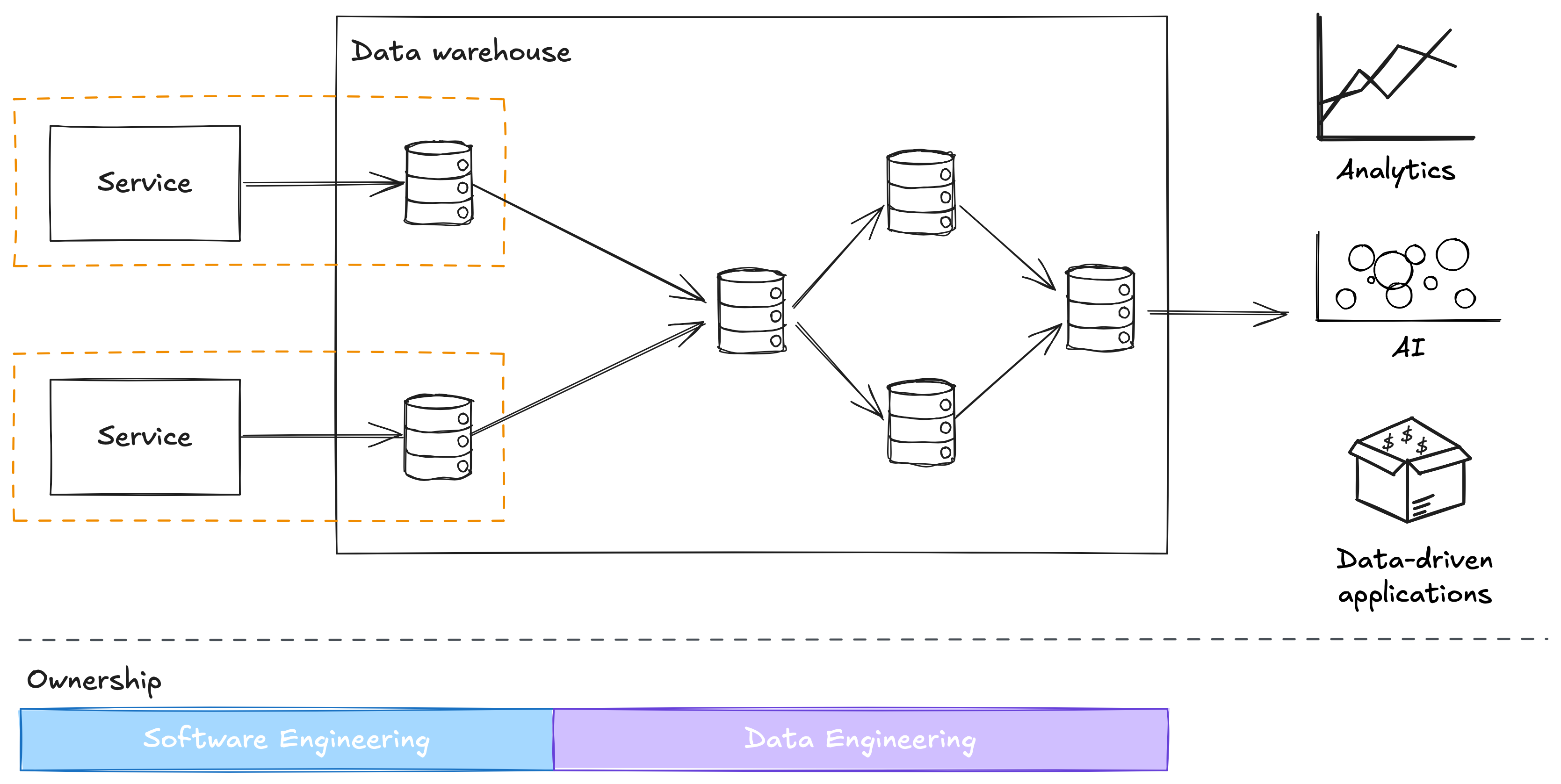
We found software engineers treated this interface like any other they own.
For example, if they were considering making a change to the interface, they would log into the data lineage tool and use that to run an impact analysis to determine the impact of that change.
The key part of this story is the software engineers assumed ownership of those tables.
Once ownership is assigned, there’s no reason why they can’t use the same tools as data engineers to manage changes and dependencies of those tables.
Interesting links
Table Compare: Safeguarding Data Integrity at Meta
One of the ways data engineering lacks behind software engineering is how we deploy pipelines and validate their correctness on production data, but before overwriting production data. Meta describe an approach they have developed.
Alignment in the Age of Autonomy by Winfried Adalbert Etzel
Good article on alignment through platforms.
How Wix Cut 50% of Its Data Platform Costs - Without Sacrificing Performance
Data warehouse costs are an issue for many of us, and this is a good read on how Wix tackled those costs.
Being punny 😅
I had no idea what I was supposed to be doing in the chicken suit yesterday, so I ended up just winging it.
Thanks! If you’d like to support my work…
Thanks for reading this weeks newsletter — always appreciated!
If you’d like to support my work consider buying my book, Driving Data Quality with Data Contracts, or if you have it already please leave a review on Amazon.
Enjoy your weekend.
Andrew