Separating the contract UI from the platform
Hello!
First, some personal news:
After nearly 8 years I’m leaving GoCardless. It’s been a great journey, building a data platform from scratch at a scale-up, but it’s time for something new. I’m still exploring what that will be and will take some time to consider that over the summer.
So, if you need a leader or engineer for your data platform/engineering teams, let me know :)
I’m also using this free time to do some small engagements, including speaking at some companies, running my workshops at others, and some light consulting.
If any of that is of interest to you, hit reply!
Now on to the newsletter…
Today I write about how separating the contract UI from the platform allows you to build the platform and its tools once, while also meeting users where they are.
Also links to articles on data ROI, a data platform built with Hudi, and polyform modelling in a data mesh.
Separating the contract UI from the platform
To support the adoption of data contracts you need to meet your users where they are.
However, you may have a number of distinct users who will be creating and managing these data contracts, including:
- Software engineers, who produce data in their services and need to publish that data to the data platform
- Service owners, who own services such as Salesforce and Zendesk that generate data that is important for key internal processes
- Data engineers, who build on top of these data sets to provide data products for use in data applications
Each of these will have different workflows you need to integrate your data contracts into.
For example, software engineers might prefer to manage their data contracts in code, alongside the code that creates this data.
While data engineers might prefer to define then in YAML, stored alongside their SQL-based transformations.
And service owners might need a web-based interface that is driven from APIs provided by the services they own.
As a data platform team, you need to meet each of those requirements. But you also need to ensure you do so sustainably and build a standardised data platform you can support over the long term.
You do that by separating the data contract definition from the platform driven by it.
That way, you’re not implementing many ways to manage access management, apply data retention policies, and so on. Those are implemented once and used by everyone.
For example, you might include in your data contract some data categorisation (is it PII, how will it be anonymised, etc), and using this categorisation you can automate data retention within your platform.
This data retention service needs that categorisation in a format it can understand. But, that does not have to be the same format the users are entering.
You can have some middleware sitting between the user-facing data contract and the platform-facing data contract.
The user-facing data contract is still the source of truth. It’s merely deployed as a separate artefact when changes are made.
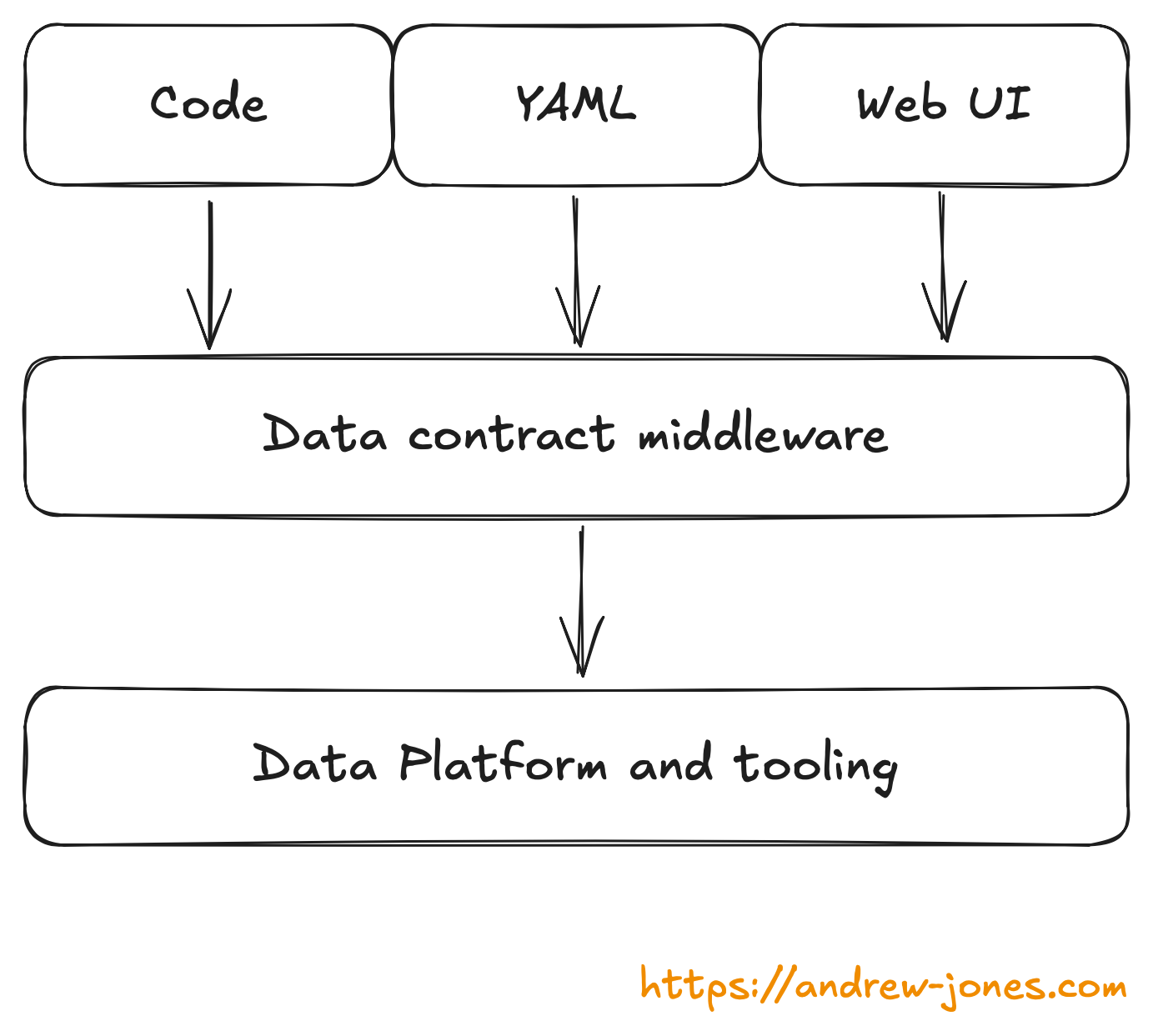
This separation allows you to build the platform and its tools once, while also meeting users where they are.
Interesting links
The Data ROI Paradox by Lior Barak
So many data leaders struggle to explain the ROI they are providing. This is a nice overview of how to estimate that ROI.
Modernizing Data Infrastructure at Peloton Using Apache Hudi by Amaresh Bingumalla, Thinh Kenny Vu, Gabriel Wang, Arun Vasudevan in collaboration with Dipankar Mazumdar
Interesting write up of Peloton’s transition to Apache Hudi as part of the efforts to modernise the data platform.
Polyform Data Modeling in the Mesh by Martin Chesbrough
Exploring how to approach data modelling in a distributed architecture such as data mesh.
Being punny 😅
I have only one joke about time. I don’t have a second.
Thanks! If you’d like to support my work…
Thanks for reading this weeks newsletter — always appreciated!
If you’d like to support my work consider buying my book, Driving Data Quality with Data Contracts, or if you have it already please leave a review on Amazon.
Enjoy your weekend.
Andrew