Federated computational governance with data contracts
Hey, hope you’ve had a good start to June! I’m writing to you from Antwerp, Belgium, where I’m attending the inaugural Data Mesh Live conference. Looking forward to a great day of learning and meeting before my talk later.
Today’s newsletter is the final part of my series on implementing data mesh, and today we’re looking at federating and automating data governance with data contracts. See also:
- Part 1: The challenges of implementing a data mesh
- Part 2: Implementing domain ownership with data contracts
- Part 3: Defining data products with data contracts
- Part 4: Driving self-serve data platforms with data contracts
There’s also links to articles on the future of Kafka, two opposing links on Iceberg, a new tutorial for data contracts, and a travel-related pun.
Plus, a fantastically detailed review of my book, which for this week only is 35% OFF both print and ebook!
Federated computational governance with data contracts
Data mesh describes how to decentralise data. However, one of the concerns with a decentralised model is how to maintain data governance.
That’s why data mesh has this principle of federated computational governance, which describes how to ensure that data is managed effectively while enabling data producers to operate with greater autonomy.
The word governance is well understood, but it’s the others that are important:
- Federated, because with data mesh we’re allowing different parts of the business to create and maintain data products with autonomy, while still maintaining standardisation and governance that has been defined centrally
- Computational, because with data mesh we automate the implementation of data governance, providing tools that implement these centrally defined rules
However, for this automation to be possible, these tools need to have enough context about the data to apply the governance rules to the data.
That context is provided by the data contract.
Let’s take data anonymisation and retention as an example.
We add categorisation into the data contract, defining whether a field contains personal data and, if so, how it should be anonymised when that data has passed its retention period or in relation to a deletion request.
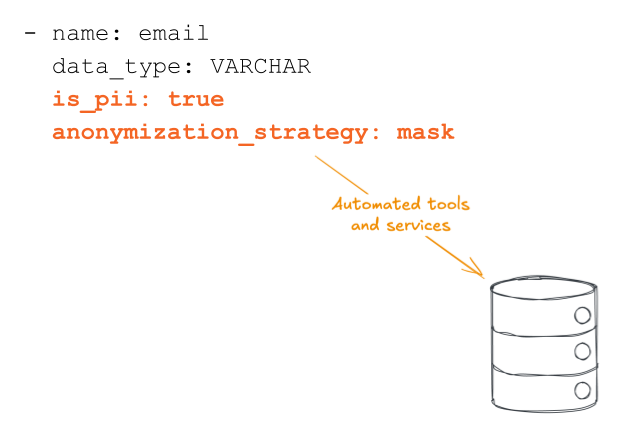
But they don’t need to know the different triggers that would cause a record to be anonymised (they don’t need to be GDPR experts!).
They also don’t need to implement their own tooling to anonymise the data.
The data platform does this, via data contracts.
The tools provided by the data platform codifies the centrally defined governance rules. They then runs those rules over all the data described by a data contract.
These tools don’t care about what the data is or why this field needs to be anonymised. They just need enough context to discover the data and run the rules.
Other examples include:
- Use similar classifications to automate access controls
- Automate the data lifecycle management (creation, deletion, backups, etc)
- Populate a central data and processing catalog from all data contracts
As I wrote last week, in the ~5 years we’ve been doing data contracts we’ve implemented all our data platform capabilities through data contracts, and that includes the implementation of our data governance policies.
Data contracts are the only way I’m aware of to successfully implement federated computational governance.
35% OFF my book, this week only!
For this week only my book Driving Data Quality with Data Contracts is 35% when you buy directly from packt.com using the code DATA35.
If you’re still on the fence, check out this fantastically detailed review of my book here written by Winfried Adalbert Etzel.
Or this AI-generated summary of Amazon reviews:

Interesting links
Kafka: The End of the Beginning by Chris Riccomini
Interesting post looking at whether it’s time for an evolution of streaming, i.e. something other than Kafka. I have two thoughts.
First is that there are already cloud-native solutions that meet the needs of many, for example Google Cloud Pub/Sub, AWS Kinesis, etc.
Though of course there are use cases that do need the power of Kafka, and my second thought is what is missing for those users that highlights the need for something better/newer than Kafka? I’d guess it’s to reduce the total cost of ownership, which is often a problem, but with Confluent running Kafka for you on any cloud and Google running it for you on their cloud the cost of ownership has been reducing.
However, I do agree that stream processing is still harder than it ought to be, but it is gradually getting easier.
The Open Table Format Revolution: Why Hyperscalers Are Betting on Managed Iceberg by Simon Späti
An in-depth overview of Iceberg and the kind of stack it can enable.
But…
Apache Iceberg Isn’t Coming To Save You by Benjamin Rogojan
Which is also how I feel about Iceberg. Nice tech, but unlikely to solve big enough problems to justify a migration to.
Data Contract & Product Experimentation by Jean-Georges Perrin
Jean-Georges Perrin (JGP) has started running hands-on tutorials to demystify data contracts and data products, using the Open Data Contract Standard from Bitol. You can register your interest with this link.
Being punny 😅
I hate hotel bath towels. So think and fluffy, I can’t even close my suitcase.
That’s all for this week. Till next time!
Andrew