Driving self-serve data platforms with data contracts
Hey friends! Welcome to another edition of my newsletter.
I’ve actually been on holiday all week with the family, but if my automation is set up correctly this will be dropping in your inbox on a Friday as usual!
This is part 4 of my 5 part series on implementing data mesh, and today we’re looking at driving self-serve data platforms with data contracts. See also:
- Part 1: The challenges of implementing a data mesh
- Part 2: Implementing domain ownership with data contracts
- Part 3: Defining data products with data contracts
There are also links to articles on building an anomaly detection system and an incomplete skills a senior engineers need, beyond coding.
Enjoy!
Driving self-serve data platforms with data contracts
Last week I wrote that while the data contract defines the data product, that’s just documentation, and documentation tends to lose its correctness and value quickly as the data evolves and changes.
That’s why moving the data contract beyond documentation is so important. It increases the usefulness of this documentation, and of the metadata, and ensures they will be kept up to date as data and systems change.
Luckily, the data contract can move far beyond documentation.
In fact, it can drive an entire data platform.
Why the self-serve data platform is important in data mesh
Data mesh is explicitly decentralising data creation and management. It’s no longer just the central data team who can create data products, it’s a number of different teams across the organisation.
The self-serve data platform enables each of these teams to do so using standardised and compatible tooling. This ensures these data products can easily integrate and communicate with one another, facilitating cross-domain collaboration.
Being completely self-serve removes the central data team from being a bottleneck and increases the autonomy of data owners, allowing them to make changes to the data as they need to. Furthermore, this autonomy breeds a sense of the ownership for the data owners. It’s their data, and they can make changes to it without asking for permission to do so.
We can confidently promote that autonomy because of the guardrails we implement in the data platform, ensuring they must still follow any central policies we define, for example around change management.
Finally, investing in a platform reduces overall costs. These different data teams don’t need to reimplement the same primitives over and over again. They are implemented once, by the data platform team, and everyone benefits from that single investment.
The self-service data platform is essential for the success of data mesh. Even if you’re not implementing a data mesh, investing in platforms are almost always realise a great ROI.
Particularly if you invest in a contract-driven data platform.
The contract-driven data platform
The initial idea for data contracts was to create an interface through which reliable and well-structured data could be made available to consumers. Like an API, but for data.
To create an interface we first need a description of the data — the metadata — that contains enough detail to provision the interface in our system of choice. For example, we need a schema with fields and their types, which allows us to automate the creation and management of a table in the data warehouse.
Then I realised, if we can automate the creation and management of an interface from this metadata, what else could we automate if we had a sufficient metadata?
It turns out, everything.
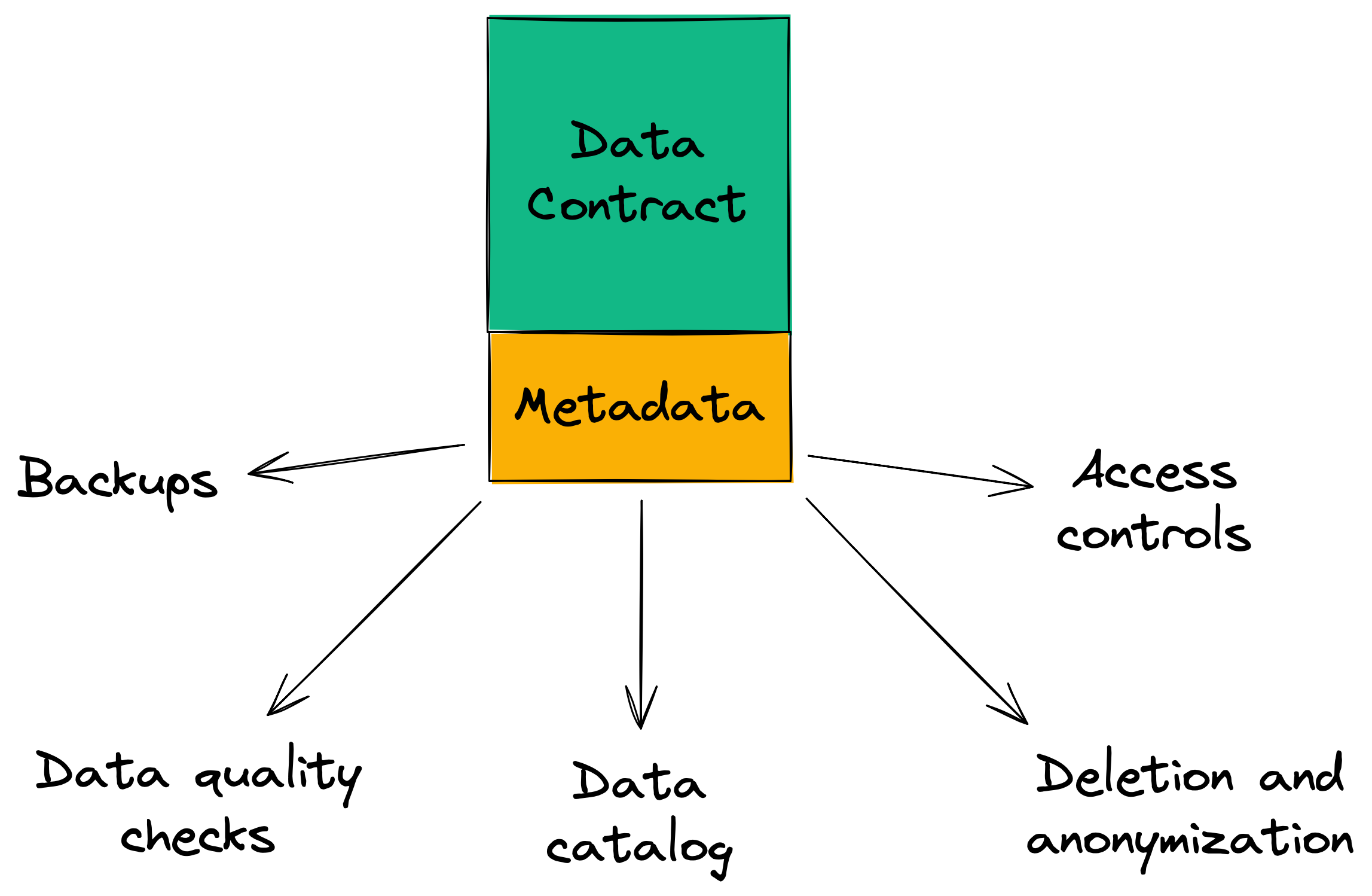
Take data quality checks as an example. We don’t need every data owner to choose a framework to write the tests in, orchestrate running the tests, set up the alerting, and so on. All we need to do is allow them to define the checks they want to run in their data contract:
- name: id
data_type: VARCHAR
checks:
- type: no_missing_values
- type: no_duplicate_values
- name: size
data_type: VARCHAR
checks:
- type: invalid_count
valid_values: ['S', 'M', 'L']
must_be_less_than: 10
And the platform runs these checks for them, on the right schedule, and sending the alerts to them if/when these checks fail.
This is great for the data owner. They can focus on creating and managing great data products that meet the needs of their users, not wasting their cognitive load worrying how to run their data quality checks.
It’s also great for the data platform team to build in this way. Any capability they add to the data platform will immediately be adopted by all data owners and to all data managed by data contracts.
Another example might be populating a data catalog. You don’t need to have data owners populate a separate system with the documentation, ownership, data quality checks, and so on. Simply have the platform register all data contracts and use that to populate the data catalog.
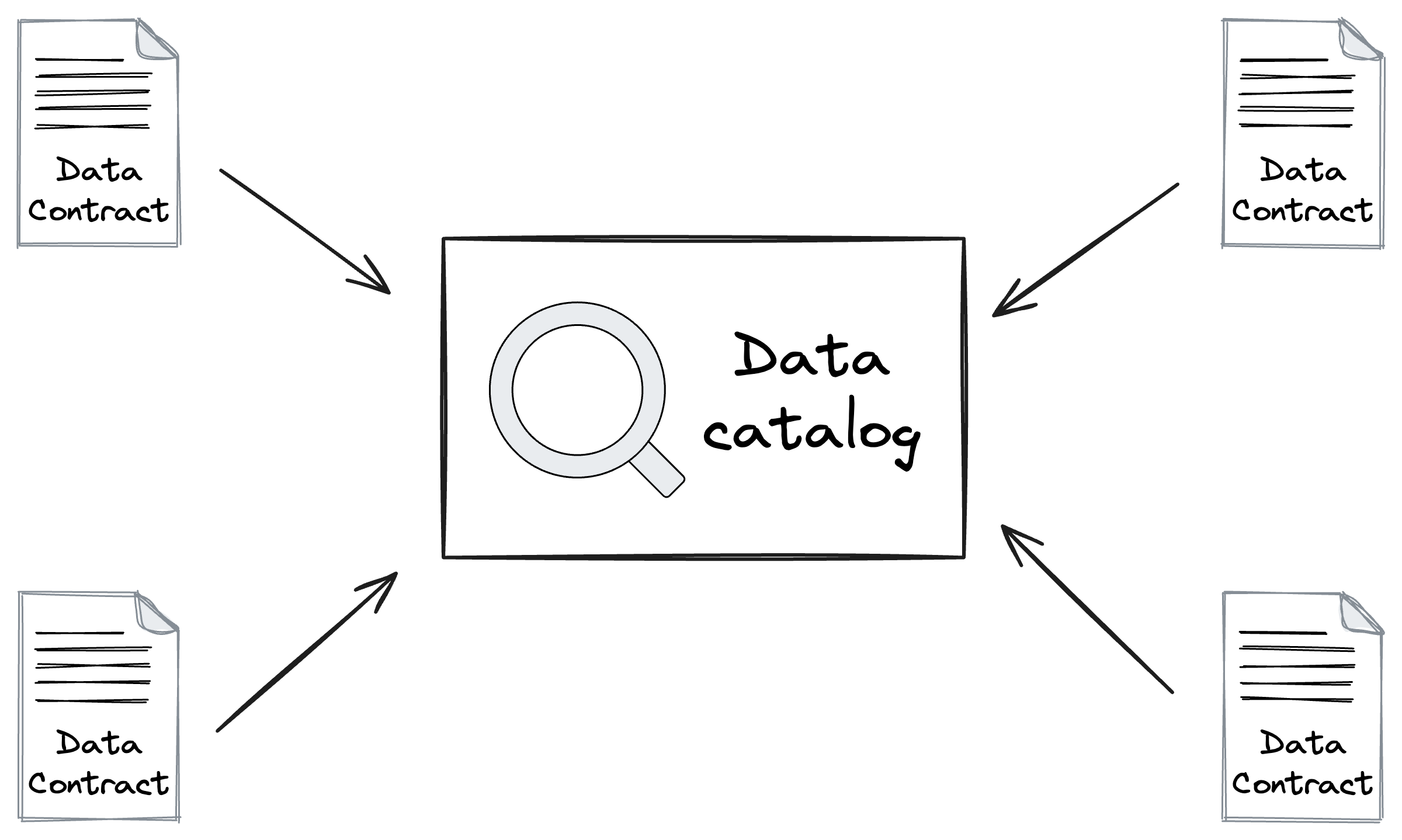
Data contracts are a simple idea. Your just describing your data in a standardised human- and machine-readable format.
But they’re so powerful.
Powerful enough to build an entire data platform around.
I’ll discuss more examples when I talk about data governance in next weeks post on federated computational governance. Till then!
Interesting links
Anomaly Detection in Time Series Using Statistical Analysis at Booking.com by Ivan Shubin
Interesting approach to building their own anomaly detection.
An incomplete list of skills senior engineers need, beyond coding by Camille Fournier
Not new, but timeless advice for anyone looking to become more senior.
Being punny 😅
I used to play piano by ear, but now I use my hands.
Thanks! If you’d like to support my work…
Thanks for reading this weeks newsletter — always appreciated!
If you’d like to support my work consider buying my book, Driving Data Quality with Data Contracts, or if you have it already please leave a review on Amazon.
Enjoy your weekend.
Andrew