Shifting Left: How Data Contracts Underpin People, Processes, and Technology
Hey, hope you had a good week!
This week I’ve published an in-depth article on shifting left, which is previewed below and available in full on the Confluent blog, plus links on docs-as-code, a new release of ODCS, and data exploration with DuckDB and Rill.
Shifting Left: How Data Contracts Underpin People, Processes, and Technology
A lot of people talk about the importance of shifting data quality left, but how exactly do we do that?
There’s a few things we need to do, which we can group as people, process, and technology.
Starting with people (as you always should), you need to get alignment between the data producers, which in many organisations include the application engineers, and the data consumers, which include data engineers and also other application engineering teams.
It needs to be clear to each of these teams what their responsibilities are, and why the quality and reliability of their data is important.
Once you have that, you can start establishing the required processes. These processes revolve around data products and data contracts.
You move to creating data products to encourage consistency and standardisation, making data a lot easier to consume and combine. It’s a shift in mindset that needs to be adopted by all data producers, including application engineering teams.
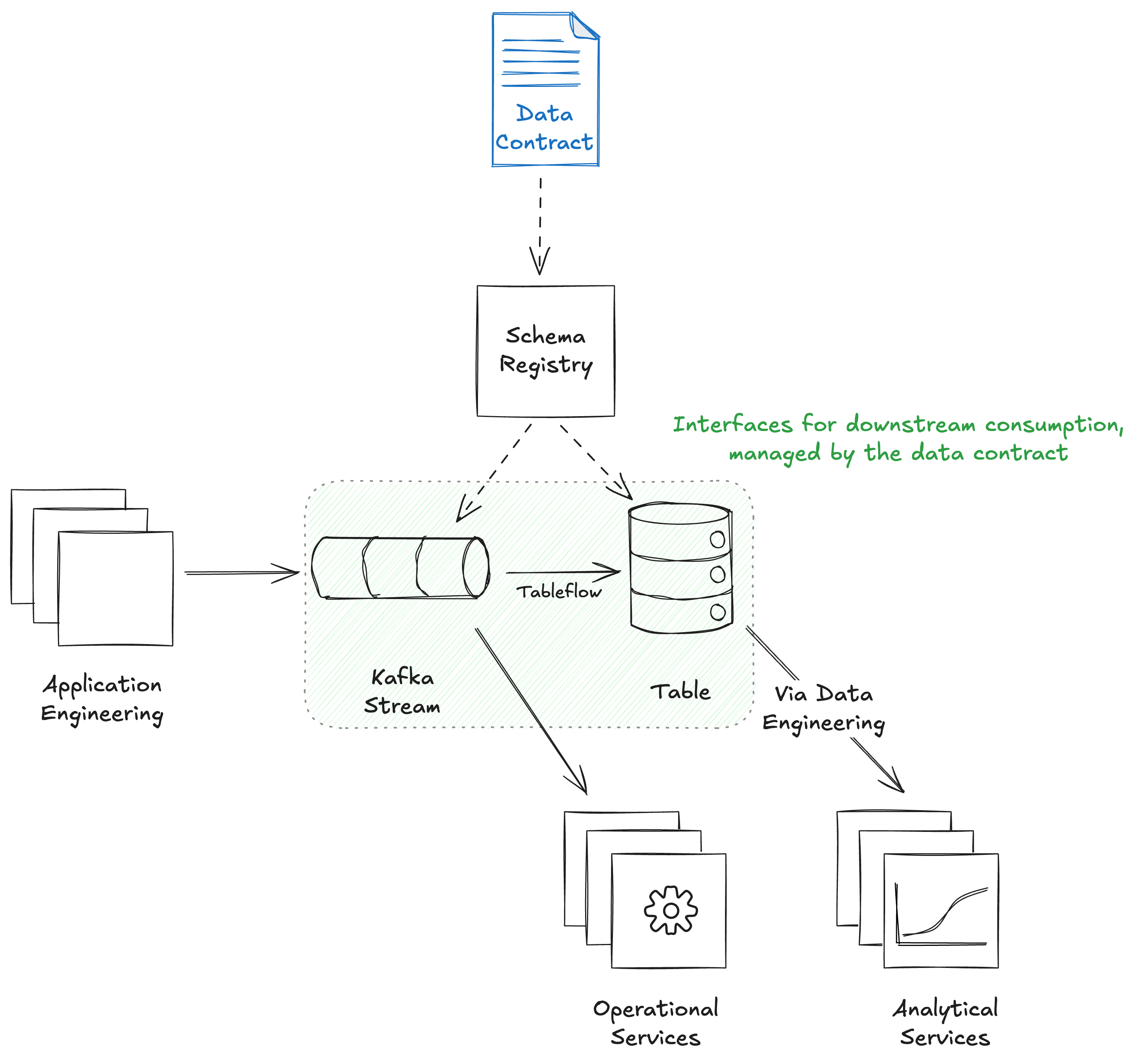
Each data product is associated with a set of metadata that describes it and simplifies its use. This metadata needs to be managed effectively and made available to other systems. That’s what the data contract does. It “wraps” the data product, capturing the metadata that describes it, and allows that metadata to flow with the data product throughout its lifecycle.
Then finally we get to the technology needed to actually implement this shift left to the left.
Imagine a system where well-structured data products exist in one place, readily accessible across various platforms. This data should be available when needed, and in the format required—be it as a stream or in a structured table. Different stakeholders, including application engineers, data engineers, and analytics and operations teams, should be able to access and use the data seamlessly.
This is the data platform we need to fully enable the shift to the left.
It should be implemented by dedicated data platform teams, who are evolving from focusing solely on maintaining infrastructure to enabling data producers, and influencing their behaviours through effective tooling.
I wrote about all of this and more in an article for the Confluent blog, including exactly how you can implement this with Kafka, Schema Registry, and Tableflow.
Interesting links
Facilitating Docs-as-Code implementation for users unfamiliar with Markdown by David Khu, Preeti Karkera, Sita Yadav and Zi Qin Yeow at Grab
While this is about documentation, it’s an interesting read in the context of data contracts.
The reason they want to adopt docs-as-code, and the standard they are aiming for, sounds very familiar:
Docs-as-Code isn’t just about engineers writing documentation—it’s about making documentation a natural and frictionless part of the development process for everyone.
While the realisation that not everyone is an engineer, and not all documentation is owned by engineering, means they needed to think of another UI if the adoption of this culture is to grow beyond engineering.
Although Grab is a tech company, not everyone is an engineer. Many team members don’t use GitLab daily, and Markdown’s quirks can be challenging for them. This made adopting the Docs-as-Code culture a hurdle, particularly for non-engineering teams responsible for key engineering-facing documents.
Often when we think about data contracts, we think about how to implement them for engineering first. And that makes sense, because that’s where most of the important data comes from.
But when you get to the place where you want to apply the same patterns to data owned outside of engineering, such as 3rd party data, then many of the lessons here also apply to those data contracts.
Version 3.0.2 of the Open Data Contract Standard released
Some minor non-breaking changes were made and released while work continues on version 3.1.
Exploring UK Environment Agency data in DuckDB and Rill by Robin Moffatt
Interesting and well detailed use of DuckDB and Rill for data exploration.
Being punny 😅
I’m reading a book on anti-gravity and it’s impossible to put it down
Upcoming workshops
- Implementing a Data Mesh with Data Contracts - Antwerp, Belgium - June 5
- Alongside the inaugural Data Mesh Live conference, where I’ll also be speaking.
- Early Bird pricing available until April 30
- Sign up here
Thanks! If you’d like to support my work…
Thanks for reading this weeks newsletter — always appreciated!
If you’d like to support my work consider buying my book, Driving Data Quality with Data Contracts, or if you have it already please leave a review on Amazon.
Enjoy your weekend.
Andrew