Wrapping legacy applications with data contracts
Hi all, hope you had a great week!
Today I’m writing about applying data contracts to legacy applications and using them to monitor data quality and assign ownership of the data to the application owner.
Wrapping legacy applications with data contracts
I tend to write about applying data contracts to applications where we have the ability to make changes to that application. But that’s not always the case.
Sometimes data comes from SaaS applications or from legacy applications which cannot be changed, such as an old ERP system.
That’s what Peter Yde Thomsen asked about on LinkedIn:
Love the full shift left paradigm, but for many practitioners (well, at least me) it […] sounds like a dream that you know that you will wake up from soon.
If I could wish for something more […] it would be for ideas and concepts on how to wrap legacy applications and their datasets with data contracts [with] automatic data quality monitoring.
Peter’s wish is my command! So, let’s look at how you would use data contracts to empower application owners to take responsibility for the quality of their data.
Ideally, you still want to go as left as you can, because the earlier you catch the problems the lower the impact and the quicker the resolution (I’ll be talking more about that in a virtual meetup next week). So, in this post I’m going to show you how to empower the application owner to take responsibility for the data coming from their legacy application.
The first thing to consider is whether they are ready/willing to take on this responsibility. As I’ve written before (and is the focus for much of my book), to do this you need to articulate why they need to take on this responsibility, and why that’s good for your organisation. For example:
- How many data incidents are being caused by these data quality issues?
- What’s the impact/cost of those issues to the business?
- How many hours of wasted work is it causing?
- What applications of the data is this preventing?
And so on.
It’s really just the same arguments people make in organisations all the time whenever you have a dependency on another teams service/process/data that needs to be improved.
Once you’ve made that argument, you can start thinking about how to implement a solution to empower application owners to take responsibility for the quality of their data.
In this solution we’ll be using a data contract as the place where we capture that responsibility and codify the data quality expectations we have.
Why data contracts
Data contracts are a great place to capture the data we need about the data — the metadata.
They can contain whatever metadata is needed to help build the tools needed to effectively create and manage data. In this case, we need at least the following:
- Owner
- Schema
- Data quality rules
These data contracts must always be owned by the data owner. Only they have the required context to populate it and only they have the ability to change the data.
It’s their data, and the data contract contains their metadata.
So, we need to provide a way for the application owners to create and maintain their data contracts. Let’s look at that next.
Defining a data contract
The application owner needs an easy way to create and maintain their data contracts. It should be as low-friction as possible and in a UI they are comfortable with.
In this case it’s worth thinking carefully about what kind of data contract UI you should provide to these application owners. For example, they may not be comfortable with code, YAML, git, etc, so you might need a web interface, which these days can be quite cheaply developed in tools like Retool and Appsmith. An even cheaper option might be a spreadsheet with validations, etc, although they tend to get complex quickly.
Whatever the interface the application owners use, the output should be a data contract that is machine-readable. That allows us to use it programatically to automatically monitor data quality.
Automatic data quality monitoring
To automatically monitor data quality we first need to capture the data quality rules. We capture these in the data contract, and those rules are owned by the data owners.
Once we have those rules we can run them in production against the data as it is extracted from the legacy application. If those rules fail you can then send an alert to the application owner (e.g. by email, Slack, etc).
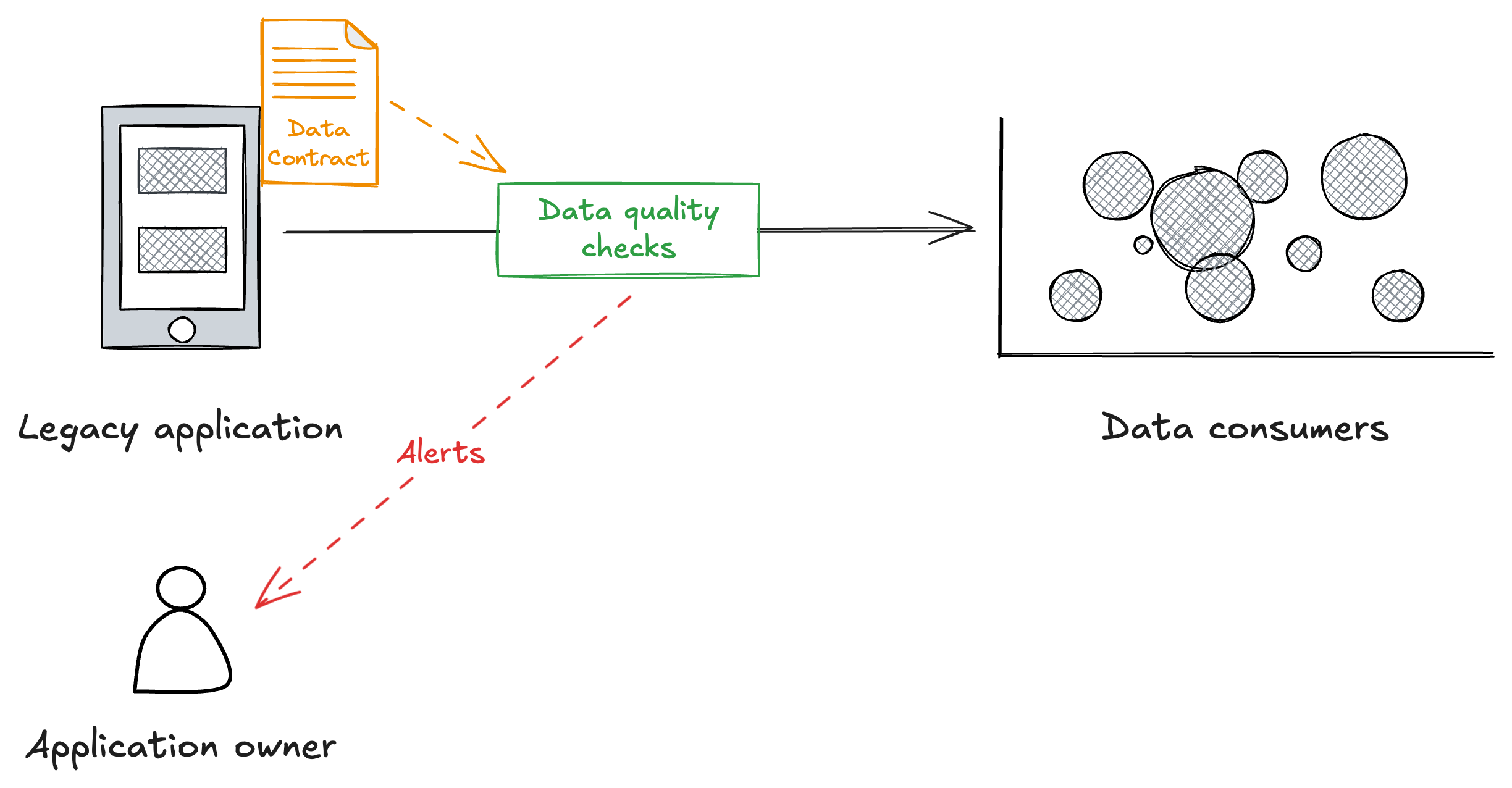
- The application owner is assigned ownership and responsibility for the data
- The application owner defines the data contract and the data quality rules they are comfortable with meeting
- Those exact same data quality rules are ran in production
- Alerts for failing rules are routed to the application owner
It’s now clear that the application owner is responsible for the quality of this data, and we’ve empowered them to take on this responsibility by allowing them to define the data contract, and the rules within it, and routing alerts to them.
This is also gives consumers greater confidence in the data. They too can see the data quality rules that are defined and know they are running in production. As an added benefit, these data quality rules provide great context on what they should expect from the data.
This is a great start! But there’s even more we could do. We could:
- Define SLOs in the data contract, and monitor those in production.
- Capture more documentation in the data contract, including semantics, limitations, etc.
- Categorise the data in the data contract, and use that categorisation to implement governance tooling.
This may not be the “perfect” picture I painted last week, and it does have some downsides. The data has already left the upstream application and could be already in downstream applications, so the impact could already be quite large before the alert is addressed (although a circuit breaker pattern would help with that). Similarly, it may be too late to revert the breaking change in the application.
But with legacy applications our options are more limited. By wrapping them with data contracts we can make a great step forward in improving the quality and management of your data.
Interesting links
Data vs. Business Strategy. Which is Responsible for What? by Jens Linden, PhD
This is a good read on how data can be leveraged and why it should be part of the overall business strategy, not a separate data strategy.
Towards composable data platforms by Jack Vanlightly
Interesting article on the composability enabled by the risk of open table formats. Anything that helps reduce the need to move data around is worth considering.
Being punny 😅
I ordered a dozen bees, but I received thirteen. That’s a free bee.
Upcoming workshops
- Data Quality: Prevention is Better Than the Cure - Virtual Meetup - March 12 4pm GMT / 12:00 ET / 09:00 PT
- I’ll be speaking about data quality and data contracts at the online Data Vault User Group meetup.
- This will probably be the last time I’ll give this particular talk, which has been well received over the last 18 months or so.
- Sign up for free here
- Implementing a Data Mesh with Data Contracts - Antwerp, Belgium - June 5
- Alongside the inaugural Data Mesh Live conference, where I’ll also be speaking.
- Early Bird pricing available until April 30
- Sign up here
Thanks! If you’d like to support my work…
Thanks for reading this weeks newsletter — always appreciated!
If you’d like to support my work consider buying my book, Driving Data Quality with Data Contracts, or if you have it already please leave a review on Amazon.
Enjoy your weekend.
Andrew