Integration without coupling, with data contracts
Data contacts has always been about solving the problem of tightly coupled data integrations.
In fact, my first public post on data contracts back in 2021 was all about replacing a tightly coupled data integration (change data capture) with data contracts.
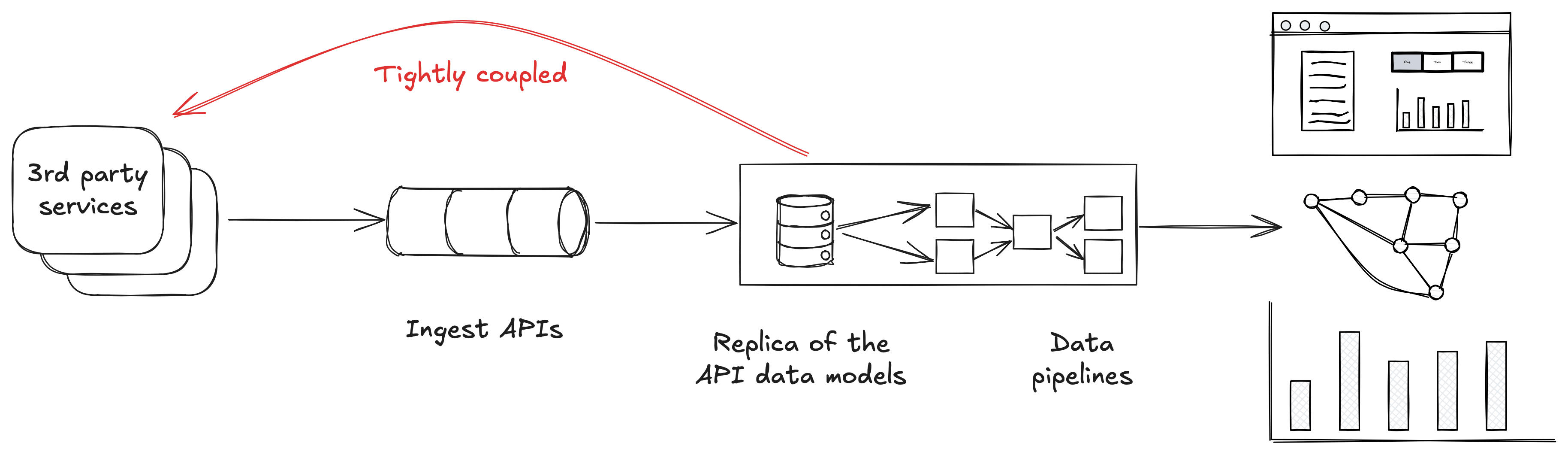
That’s just one example. Data integrations with 3rd party services also tend to be tightly coupled.
Which, considering how many we have to build, can have a great impact for your data team and for your organisation.
In this week’s post I’ll explore the problems with tightly coupled data integrations, and how we can use data contracts to solve those problems.
Tightly coupled integrations
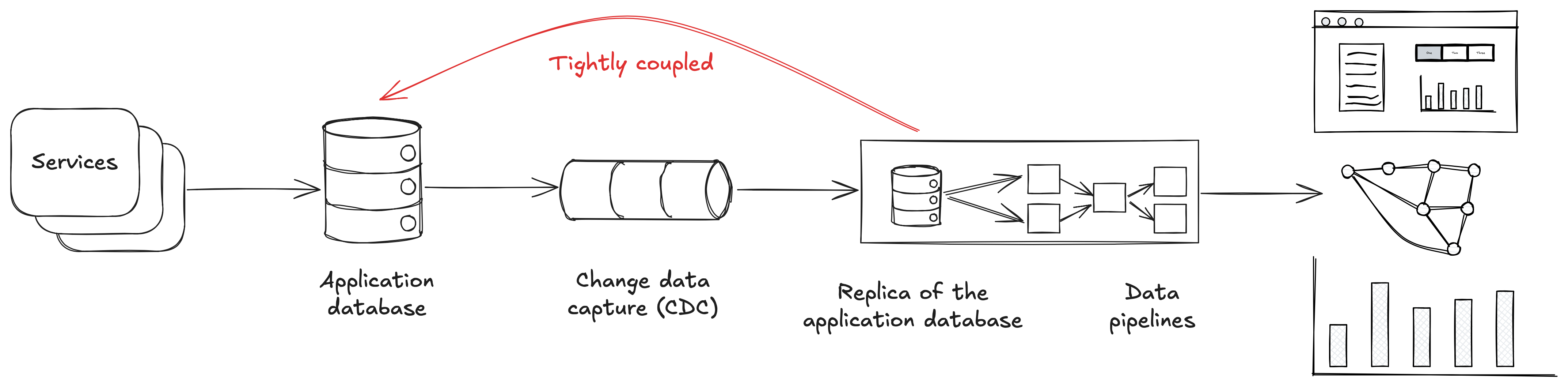
I’ve mentioned change data capture (CDC) already, and that’s a great example of a data integration solution that is tightly coupled. In this case, CDC tightly couples your data warehouse to internal data models of the upstream database.
CDC works by replicating an upstream database into your data warehouse. Everything is copied over as-is, including the tables, the schemas, and the data.
But these data models are the internal models of the upstream service. It should be expected that these data models change in breaking ways as the service evolves over time.
Because we’re tightly coupled to those models, the impact of those breaking changes spreads beyond the single codebase and throughout our data pipelines and our data warehouse.
These too tend to be tightly coupled with the source system, blindly replicating the data structures exposed through its API into your data warehouse.
zendesk_organisations, which you use as the source for your pipelines and data applications.Then the business moves from Zendesk to Freshdesk, and now you have a table called freshdesk_companies. That then requires a large migration project to migrate your data pipelines and data applications to this new structure.
A couple of years later your business moves to Help Scout, which doesn’t expose a separate organisations API, so now you just have a helpscout_customers table, and you do it all again.
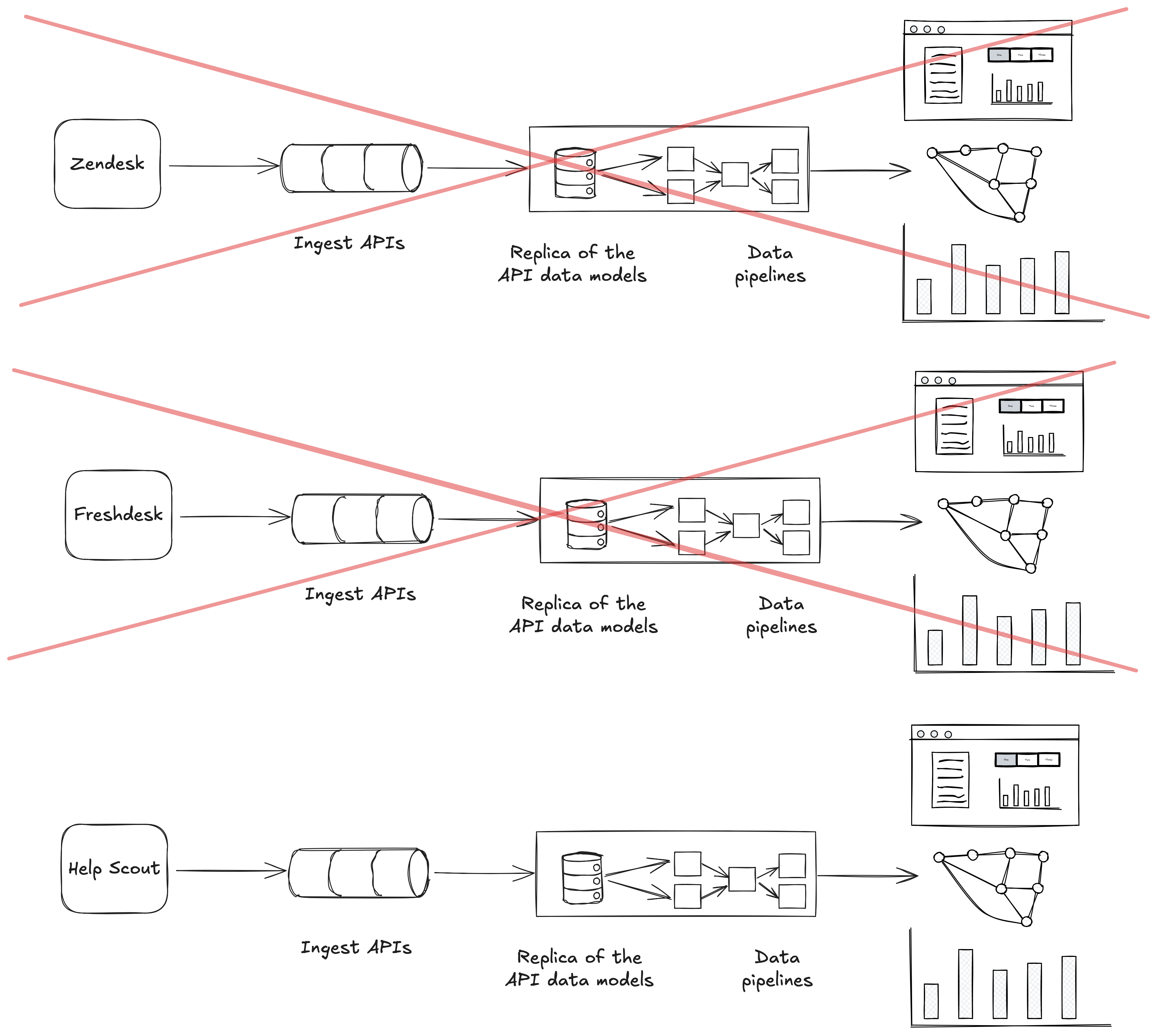
As with CDC, we need to move away from tightly coupled data integrations so the business can have more agility when deciding on the systems it uses, and to reduce the expense of doing so.
Systems come and go, and that should be expected
We should be treating the systems we are integrating with as ephemeral. They come and go.
The consumers of the data shouldn’t have to rewrite all their data applications when that happens.
This from The Data-Centric Revolution sums it up nicely:
When you invest $100 Million in a new ERP or CRM system, you are not inclined to think of it as throwaway.
But you should. Well, really you shouldn’t be spending that kind of money on application systems, but given that you already have, it is time to reframe this as sunk cost.
One of the ways application systems have become entrenched is through the application’s relation to the data it manages. The application becomes the gatekeeper to the data. The data is a second-class citizen, and the application is the main thing. In Data-Centric approaches, the data is permanent and enduring, and applications can come and go.
You systems will change. Your databases will change. But the data endures.
Given this reality, we need to move away from tightly coupling ourselves to these systems and databases and instead integrate through interfaces.
The power of interfaces
Interfaces are used everywhere in software engineering to reduce coupling.
They provide an abstraction, where a contract is defined without exposing the implementation details.
Behind the interface that implementation can change, but that does not impact downstream users.
For example, when you use a library in Java, Python, Go, whatever, you’re using it through an interface. It’s (hopefully) well documented, versioned, and easy to use. You know that you can build on it with confidence and it’s going to be pretty stable.
Things will change behind the interface, but that will not impact your usage.
APIs (application programming interfaces) are another example, and used internally between services and externally between organisations. People build entire businesses upon APIs from organisations like Stripe, Slack, and Github and can do so with confidence.
Again, things will change behind the interface (think about how much changes at somewhere like Stripe!), but that will not impact your usage.
Data typically isn’t provided through an interface. Instead we tightly couple ourselves to the systems.
It’s time we started using interfaces for data.
Data contracts provide the interface for data
Data contracts are human- and machine-readable documents that describe the data and it’s properties.
That includes the schema.
Since we have the schema in a machine-readable format, we can easily provision an interface from that schema, and have our pipelines and other consumers read from that interface.
(In practice, this interface is likely a table in a data warehouse, a topic in Kafka, etc.)
Then, instead of pulling data from the applications database via CDC, we can have services push data to that interface.
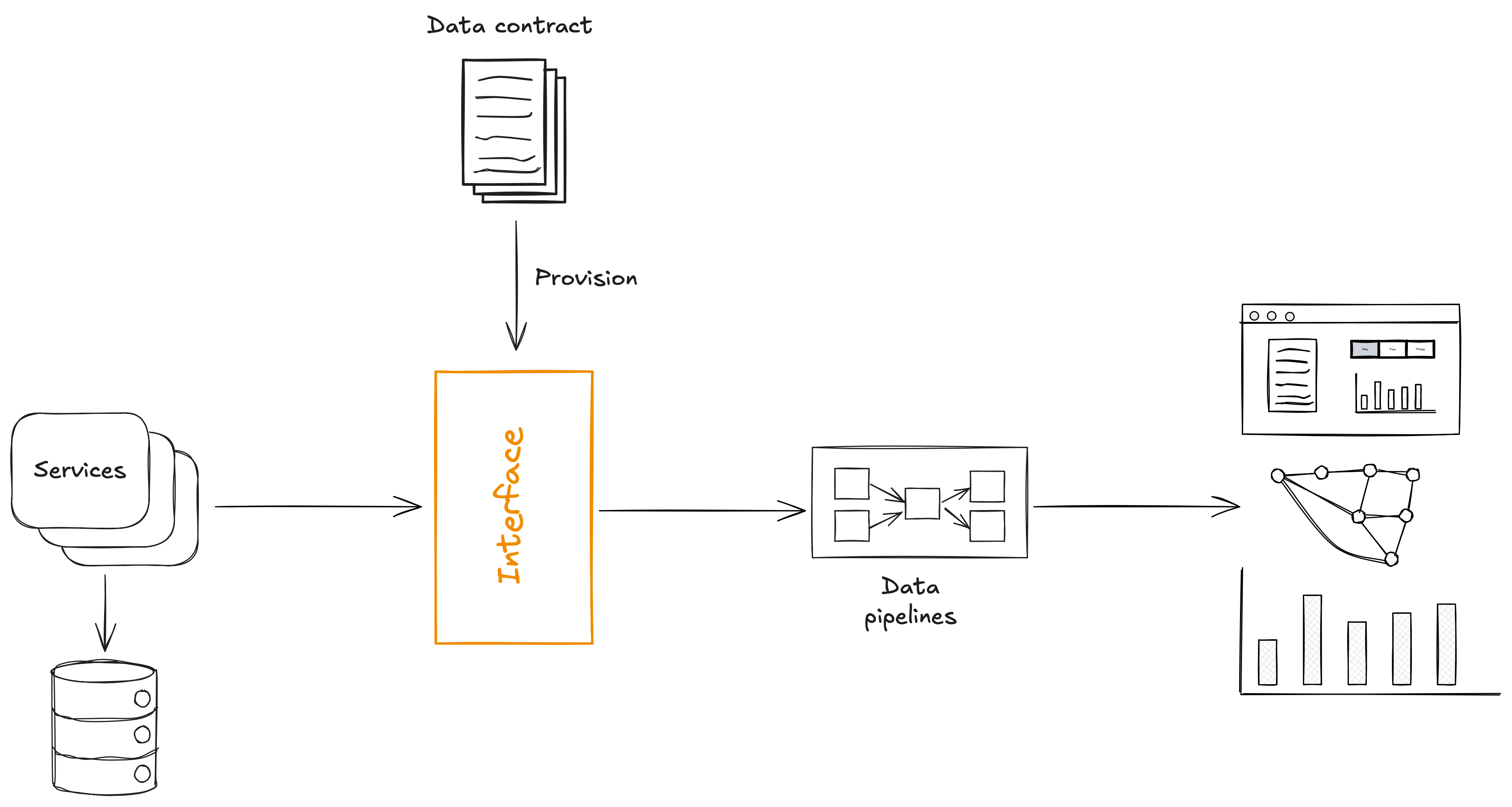
We can apply the same principles to 3rd party services.
We use a data contract to provision an interface, and transform the data from the source application to conform to the data contract.
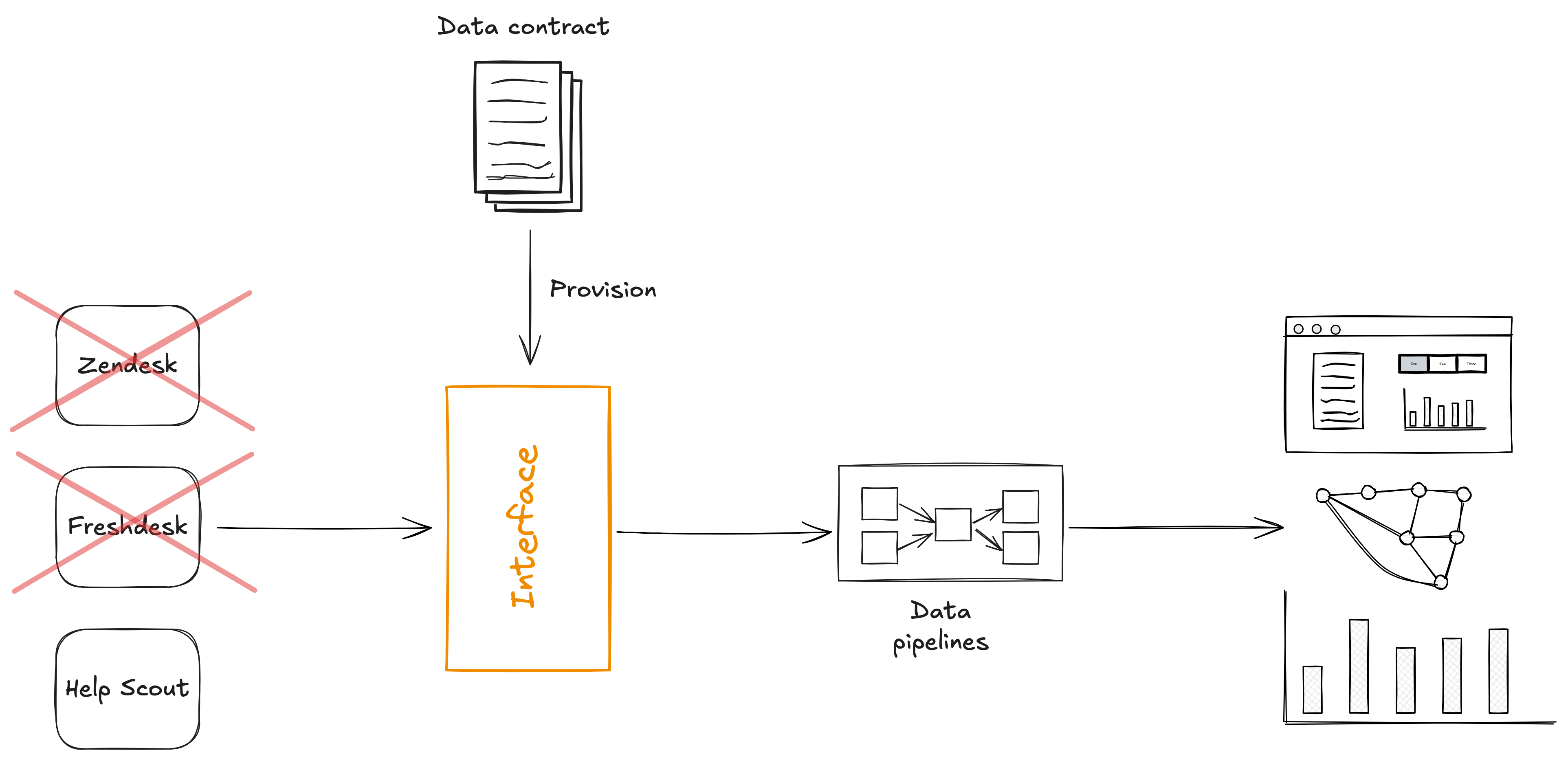
Integrating without coupling
What we’ve done here is use the interface to remove the coupling between the systems producing the data and those consuming it.
The data contract is an independent document that defines what the interface should look like, much like an API spec.
Systems will come and go, but the interface, the data contract, and that data itself endures.
Interesting links
The Hidden Currency of Leadership: Julia’s Theory of Political Capital by Julia Bardmesser
You have a finite amount of political capital you can spend at any one time. Use it wisely!
(Also, politics is often seen as a derogatory term at work. “I don’t want to get into the politics of that”, etc. But the reality is politics is just how groups of humans work together.)
Beyond the job title by Alex Jukes
Nice short read if you are a leader or aspiring to become one.
Being punny 😅
Why was the API down? It needed REST
Upcoming workshops
- Implementing a Data Mesh with Data Contracts - Antwerp, Belgium - June 5 2025
- Alongside the inaugural Data Mesh Live conference
- Sign up here
Thanks! If you’d like to support my work…
Thanks for reading this weeks newsletter — always appreciated!
If you’d like to support my work consider buying my book, Driving Data Quality with Data Contracts, or if you have it already please leave a review on Amazon.
Have a lovely weekend ❤️
Andrew