Implementing change management with data contracts
This is part 5 and the final part in my Data Reliability series. You can read the rest of the series on my website.
Yesterday we arrived at change management as the solution for our data reliability problem. Now, finally, we can start to implement that solution.
In theory, you don’t need tech to implement change management. You can define processes for people to follow, assign people to carry out those processes, and have someone review every change before it is made.
In practice though that doesn’t usually work. Having people in the loop for every change is:
- Too error prone
- Too expensive
- Too slow
Worse, many breaking changes will get missed, and so you’ll still have many preventable data incidents caused by the lack of change management.
So, we need to automate this.
Exactly how you do that depends a bit on where your data comes from. Is it from a database? A SaaS tool? A third party?
I’ll use getting data from an upstream database as an example, as for many organisations that’s where their most important data is, and I’ll assume you’re currently getting the data through change data capture or a similar ELT process.
You could put change management on those tables in the database, preventing software engineers from making changes to their database unless they follow the change management process.
However, often those systems, and the database that drives them, need to change frequently as they develop new features, improve performance, and so on. So now you’re slowing software engineers down considerably, and that may be too high a cost.
A better approach is to move away from directly building on an interface.
Interfaces are powerful. That’s why we see them everywhere in software engineering. In fact, I’d say they are essential when you want to depend on something provided by someone else.
The obvious example is an API. People build entire businesses upon APIs from organisations like Stripe, Slack and Github and can do so with confidence because they are extremely stable. They rarely change, and if they do there will be a new version and a migration path to that new version (i.e. there will be a change management process applied).
Behind the API the systems at this organisations are changing all the time. New features are being developed, performance is being improved, legacy systems are being decommissioned - but the API itself is stable.
Most organisations also use APIs internally for communication between systems, and do so for exactly the same reasons.
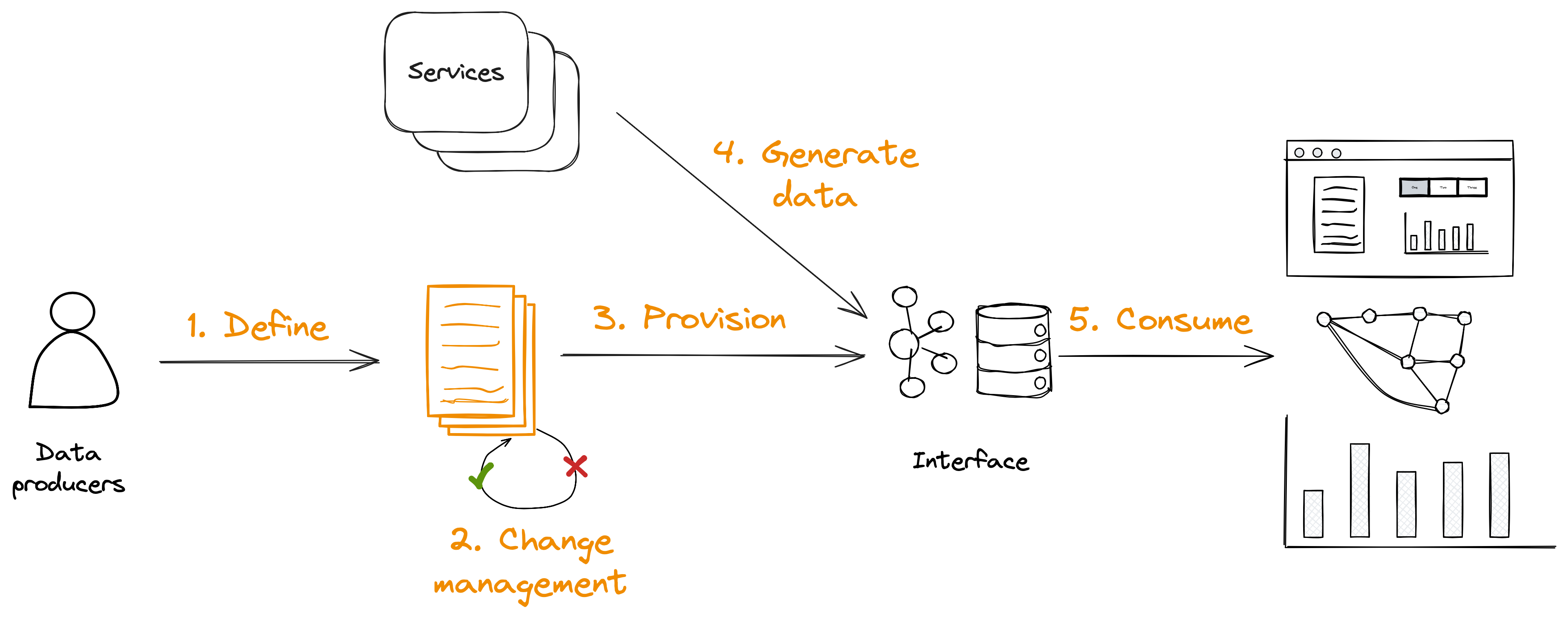
So if we want to apply change management to our data, without slowing down or preventing changes to our internal systems, we need an interface for our data.
That interface is the place where data is consumed from. Typically that’s a table in a data warehouse, but it could also be a Kafka stream, a structured file in a data lake, and so on.
To provide data through a change managed interface, we need to:
- Define the interface in a human and machine readable format
- Implement the change management checks on that definition
- Provision and manage the interface from the definition, thereby applying change management to the interface
- Change our data generating services to publish data to that interface
- Ensure our data consumers consume only from that interface
The data contract is the place where we define the interface.
That’s the end of this series, I hope you enjoyed it. If you have any feedback, questions, or comments I’d love to hear them! Simply reply to this email.
Till next week.