Validating data contracts downstream
I wrote yesterday how it’s best to validate as early as possible.
But there are times that might not be possible, maybe because:
- You have hundreds or thousands of data producers, and it would take a long time to migrate
- You cannot make changes to the upstream application
In those cases you may need to implement data quality checks a bit further downstream, though still as left as possible.
One architecture to consider is shown below.
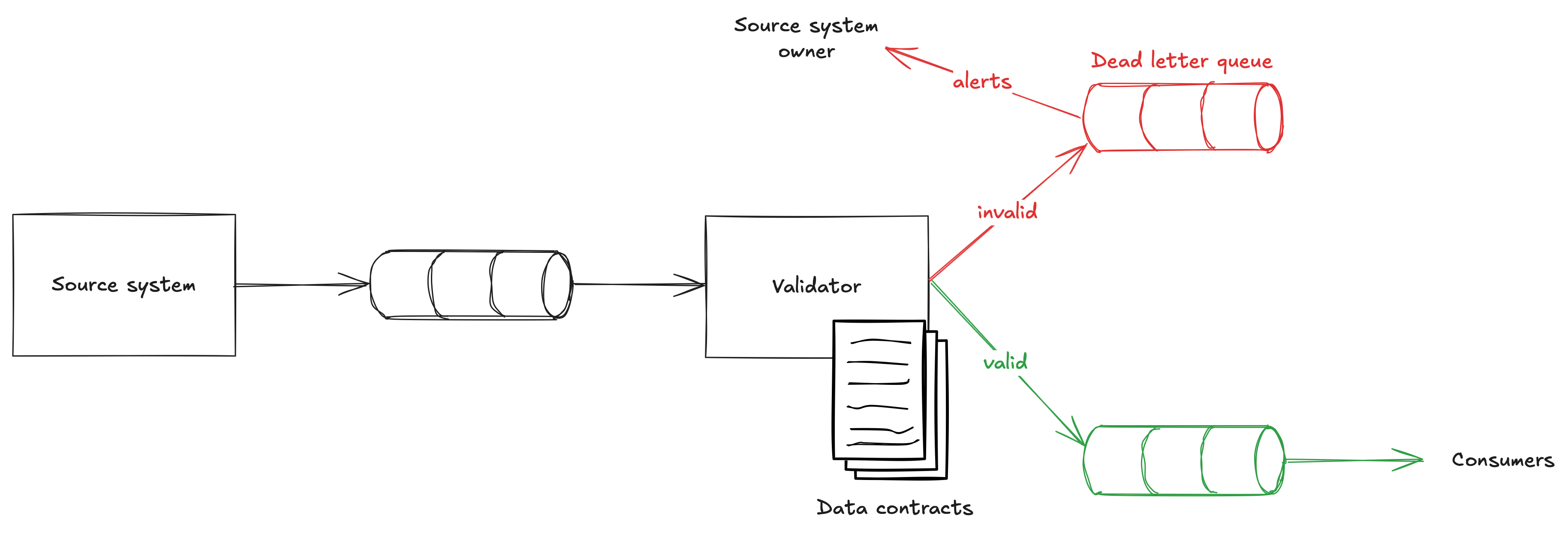
Here we have the source system write to an output stream (doesn’t have to be a stream, could be an database/data lake/whatever) and from there we have a validator performing the validations against the data contract.
If the data is valid it gets written to another stream, which is the one consumers will consume from.
If the data is invalid we write to a dead letter queue and send an alert to the source system owner.
It’s important the source system owner gets those alerts and still has responsibility for ensuring their data matches their data contract. We could make that easier by providing runbooks and tools to help them recover from data issues.
With this architecture we’re still getting many of the benefits of validating error while reducing the work needed upstream.