Reversing Conway's Law
Yesterday I wrote about Conway’s law and the challenges it causes in organisations where data teams are placed in a separate part of the organisation to where the data is generated.
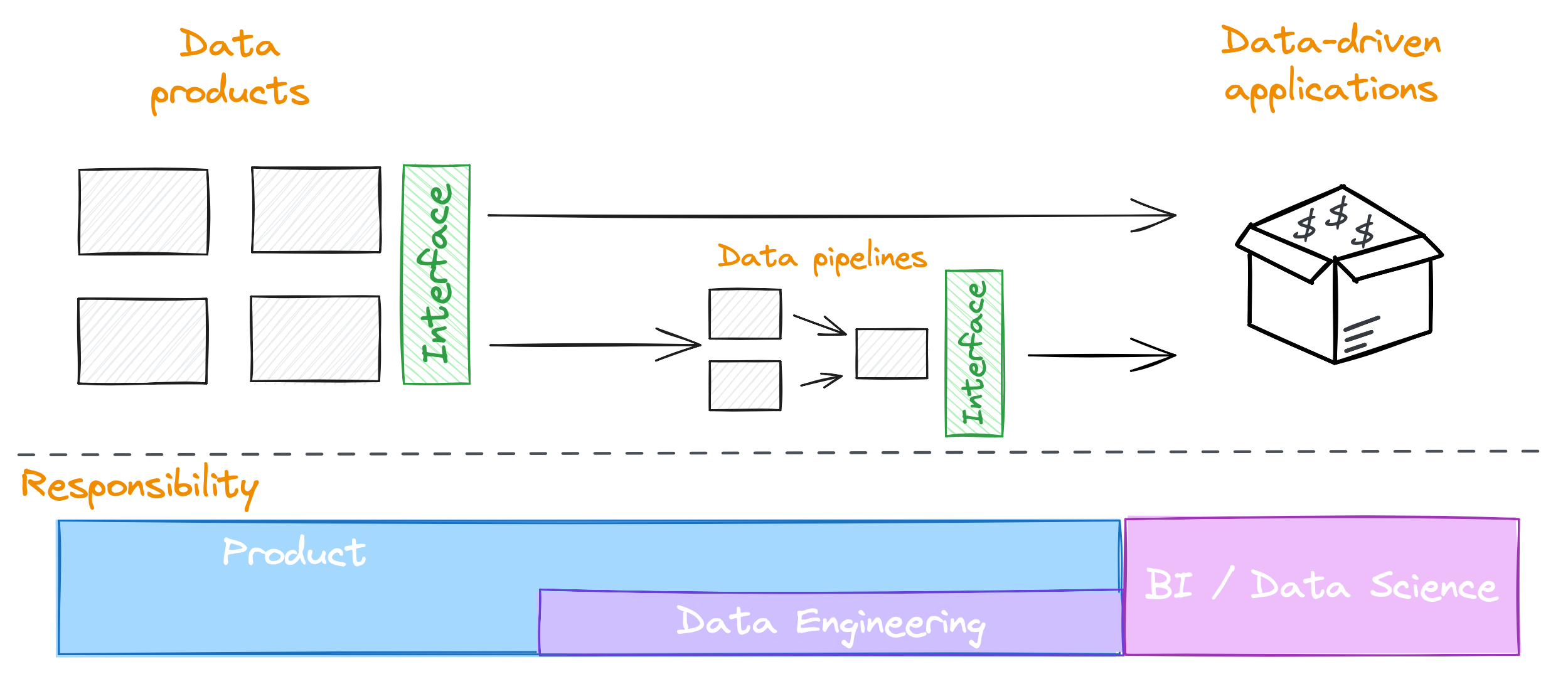
While we may not be in a position to change the organisation structure, we are able to control how our data architecture is designed and how that impacts the communication structures.
This is sometimes called reverse Conway’s law, which states that organisations will reorganise itself around their architectures.
That’s something we can use to our advantage.
For example, we can design a data architecture that makes it easy for data producers to create and manage the data they own.
On the other hand, we make it harder for unmanaged data to move around the organisation (i.e. we’re deliberately adding friction).
Over time, we’ll see more data being managed by the data producers, because that’s what is easiest for them, and they take on responsibility for that data.
They may find they start having a lot of data to own and manage, which may lead to them hiring dedicated data engineers within their team/group/division to support that.
So, by taking advantage of reverse Conway’s law, we are starting to change the organisation from the bottom-up, moving to a more decentralised model of data ownership, where those who produce the data own it and are responsible for it - reducing ETL costs downstream and increasing the quality of our data.