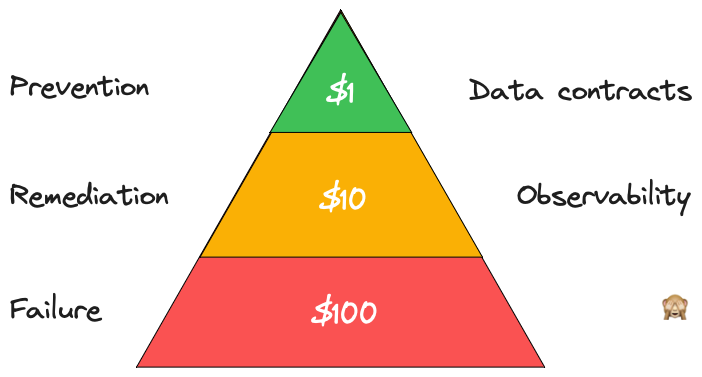
The 1:10:100 rule of data quality
𝗧𝗵𝗲 𝟭-𝟭𝟬-𝟭𝟬𝟬 𝗿𝘂𝗹𝗲 𝗼𝗳 𝗱𝗮𝘁𝗮 𝗾𝘂𝗮𝗹𝗶𝘁𝘆
One of my favourite talks at Big Data LDN was by Hannah Davies on The Building Blocks of Data Culture During Transformation.
There was a lot of great stuff to take away, but one thing Hannah mentioned was the 1:10:100 rule of data quality.
This was developed by George Labovitz and Yu Sang Chang back in 1992 and states that:
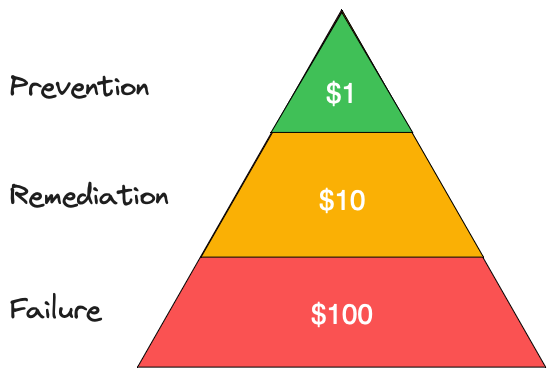
- The cost of preventing poor data quality at source is $1 per record
- The cost of remediation after it is created is $10 per record
- The cost of failure (i.e. doing nothing) is $100 per record
I don’t know about the exact numbers, but I agree with the argument! And it’s a rule that seems to be almost universal.
Health care is the most obvious example. Prevention is always better than the cure.
It also applies to software engineering, where we try to catch bugs as early as possible (observability and QA) or better yet, prevent them from making it to production (testing, continuous integration and phased rollouts).
And it applies to data quality.
Let’s look at each section of the pyramid in turn, starting from the bottom, and understand how data quality affects each phase and what solutions you can consider.
Failure — $100
Doing nothing and attempting to live with poor quality data is likely to prove expensive.
For example, maybe you have data in a data lake somewhere, but it’s hard to access and use, requiring a skilled engineer writing complex Spark code and attempt to transform it into something useful. They might eventually figure it out, but the cost is high.
Or, maybe they don’t figure it out, or the cost of attempting to use that data is so great that it’s not worth it, so you give up. Now that $100 includes the opportunity costs and the failure to deliver on your organisations business goals.
Most data teams are doing something to remediate poor quality data, so let’s look at that next.
Remediation — $10
The next level up is remediation, and this is where a lot of data teams invest their time. It includes writing tests using something like Soda or Great Expectations and deploying data observability tools such as Monte Carlo, Metaplane and Sifflet.
These are great and provide a lot of value. They help you identify data quality issues more quickly and resolve them more quickly.
However, they often alert you after the data has made it to production, so there is still a significant impact.
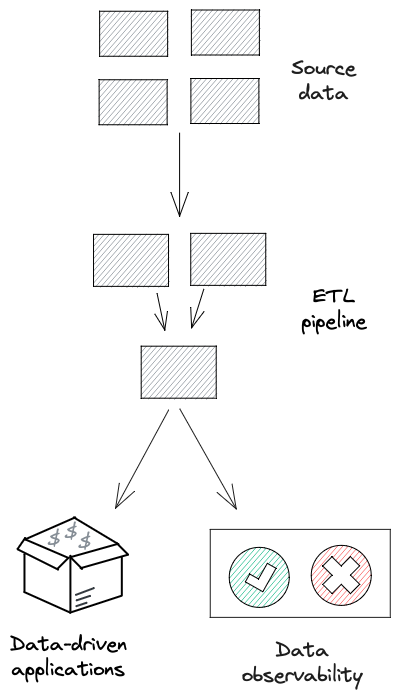
Once an issue has been identified, most data teams then attempt to “fix” the issue in their data pipelines or ETL, as it’s the only place they have the ability to make changes.
However, all of that just adds more complexity to the data pipelines. It becomes a debt that will keep slow you down now and into the future.
We also haven’t done anything to improve the quality of the data. We’ve just worked around the issue as best we could and attempted to reduce the impact of it.
The only place we can improve the quality of the data is at the source. It’s only there we have the ability to make changes to the data, how it is collected and how it is prevented.
It’s only there we can prevent poor quality data from being produced.
Prevention — $1
At the top of the pyramid we have prevention, where investing in data quality is cheapest and most effective.
To prevent data issues at the source we need to “shift left” the responsibility of data quality to those who are producing it.
If we can do that, the impact of poor quality data is reduced and can be handled before it makes its way into downstream systems.
We can also prevent common issues from occurring in the first place.
Many organisations invest little in preventing data quality issues. But the growing appreciation and implementation of data contracts is changing that.
Data contracts can be implemented at the source systems and prevent poor quality data from leaving that system.
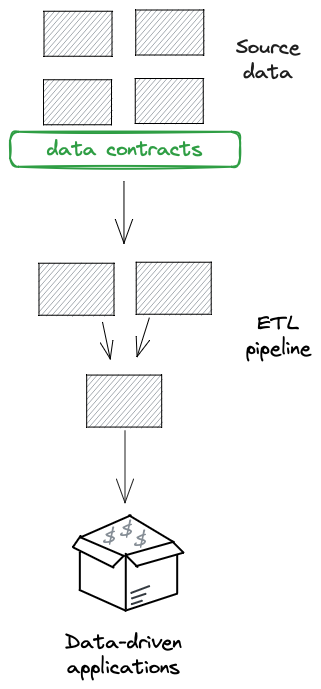
They facilitate the shifting left of data quality by enabling data producers to more explicitly define the data they are providing to the rest of the business.
Data contracts also provide the tools to make it easy for data producers to make quality data available whilst catching and handling poor quality data.
Prevention is better than the cure
As Kevin Hu, PhD wrote in his foreword for my book: “An ounce of prevention is worth a pound of cure”.
That’s why data contracts is getting so much attention at the moment, as many of us strive to improve the quality of our data and unlock its value.
Data contracts wont catch every data issue, so you should still be using observability tools if you can, and you should still be building defensively.
But prevention is always better than the cure.