Every data transform is technical debt
I enjoyed this post by Paul McMahon on how all code is technical debt. Paul argues that the more code an application has, the slower the development, due to the assumptions that exist in that code and the features they support. As such, he views all code as technical debt.
I agree, and would argue that it’s not just development speed that’s affected. The more code you have, the more risky it becomes to make a change without affecting existing features and assumptions. You can invest more in testing to reduce that risk, but that’s an increase in cost.
The maintainability of the service also gets harder the more code you have. Diagnosing an issue takes longer as there are more moving parts, and debugging is harder because you cannot fit all of the features and assumptions in your mind.
I’d also suggest this is even worse with data transformations. Often these are implemented in SQL, which is hard to test, so most of the assumptions go untested. Those data transformations are also written on data produced by others, in different code, so we lack the context on those assumptions too.
And yet, how often do we say we’ll (or get told to) “just work around it in ETL”? Some people even celebrate that! (Although, there could be other reasons why they do so…)
Each of those workarounds is a new feature, a collection of new assumptions, an increase in complexity, leading to slower development speed, reduced reliability, and increased maintenance costs.
Worse still, that workaround is itself an assumption based on business logic we don’t really own, and often a duplication of logic that already exists in an upstream service. That service, and that logic, will change over time, breaking our assumptions without notice.
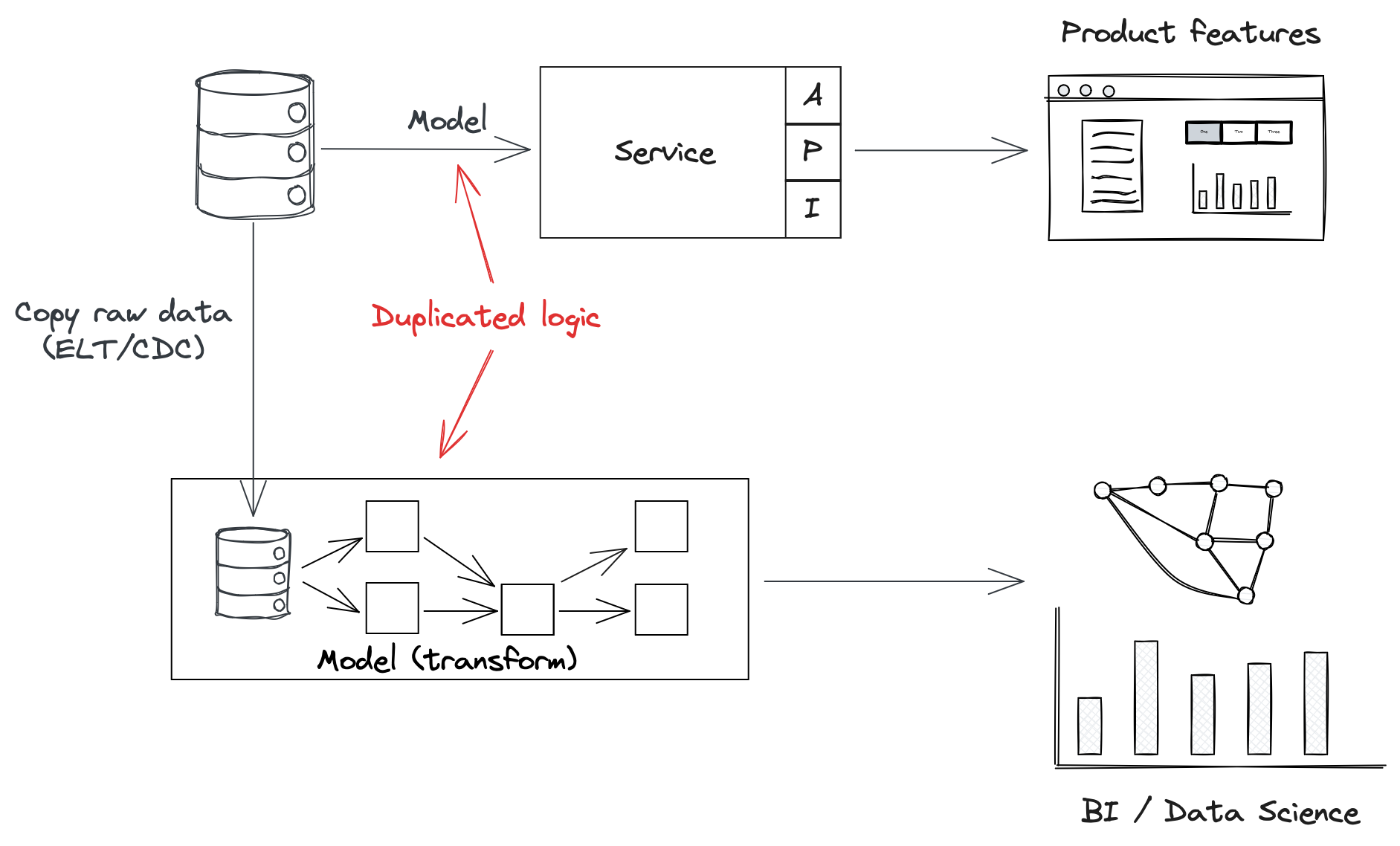
The only solution is to reduce the amount of data transformations we do.
Firstly, we should challenge the assumption we need to bring all data centrally and transform it all before it can be useful - or at least, make it a cost/benefit decision, with better knowledge of the cost of that code.
Next, decommissioning features and data transformations that are of little value will help to reduce the amount of code we have, as well us increasing our focus on delivering the most value for the organisation.
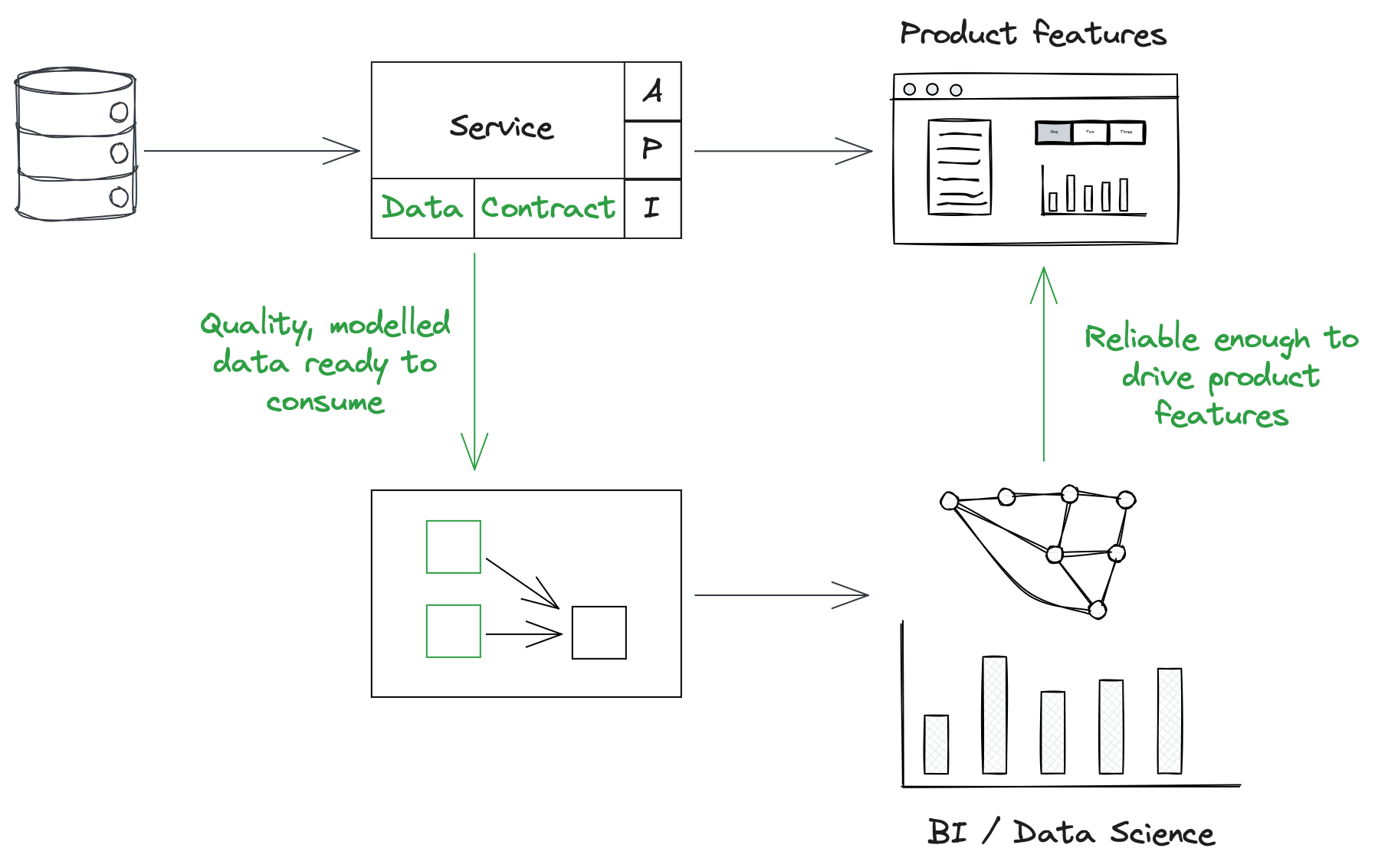
But I think the best way to solve for this is to increase the quality of data coming from the source system, reducing the logic and workarounds we need to add to the data transformation layer. Moving away from ELT and CDC and towards data contracts can help here, facilitating more explicit generation of good quality data.