Implementing Data Contracts at Gocardless
Originally published on the GoCardless Tech blog.
At GoCardless, we’re using Data Contracts to improve data quality and reliability. We’ve been on this journey for nearly a year now, and while we have some learnings we’re making great progress.
Today, I want to share a bit about how we’ve implemented Data Contracts at GoCardless.
A brief introduction to Data Contracts
If you’re not familiar with Data Contracts I recommend first reading my post from December last year where I introduced the concept and what we’re aiming to achieve with it at GoCardless, but to summarise briefly it’s the way we generate, consume and manage our data. We’re moving to a model where we are much more deliberate about the data we produce for consumption - we want it to be of good quality, with schemas, versioning and documentation.
The Data Contract defines the structure of the data, its properties, and provides the interfaces for interacting with the data - which for us is typically GCP Pub/Sub and/or BigQuery. It’s effectively an API for our data.
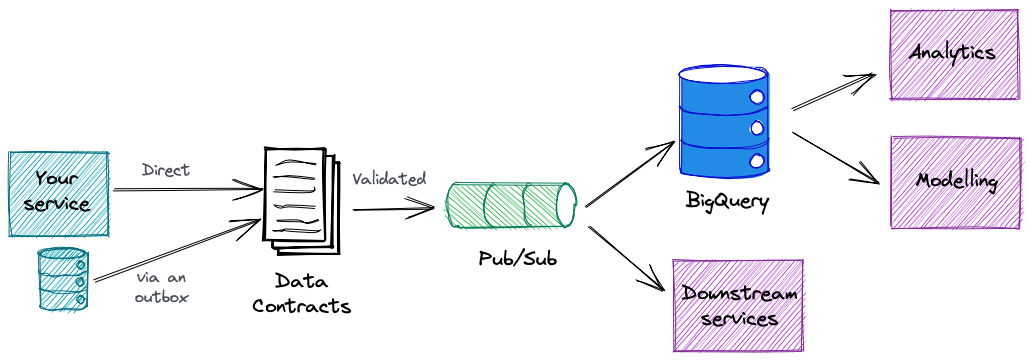
Building on top of our infrastructure platform
At GoCardless we have an excellent self-service infrastructure platform which we call Utopia. It’s how we manage our GCP resources and deploy services to our Kubernetes cluster, and aims to promote autonomy and ownership. Any configuration in Utopia should be self-servable, documented, and verifiable.
This aligns perfectly with our aims for Data Contracts! So it was a no-brainer to build our implementation on top of Utopia. It also gave us the ability to deploy and manage any service resource we needed to help our users manage their data. So that got us thinking… Given a Data Contract that sufficiently documents the data and its properties, can we set up and deploy everything we need to manage that data in accordance with our usability, security and privacy requirements? 🤔 After a quick spike, the answer was yes 🙂.
For more details on Utopia, see our “Getting Started” tutorial which we open sourced last year.
Defining a Data Contract
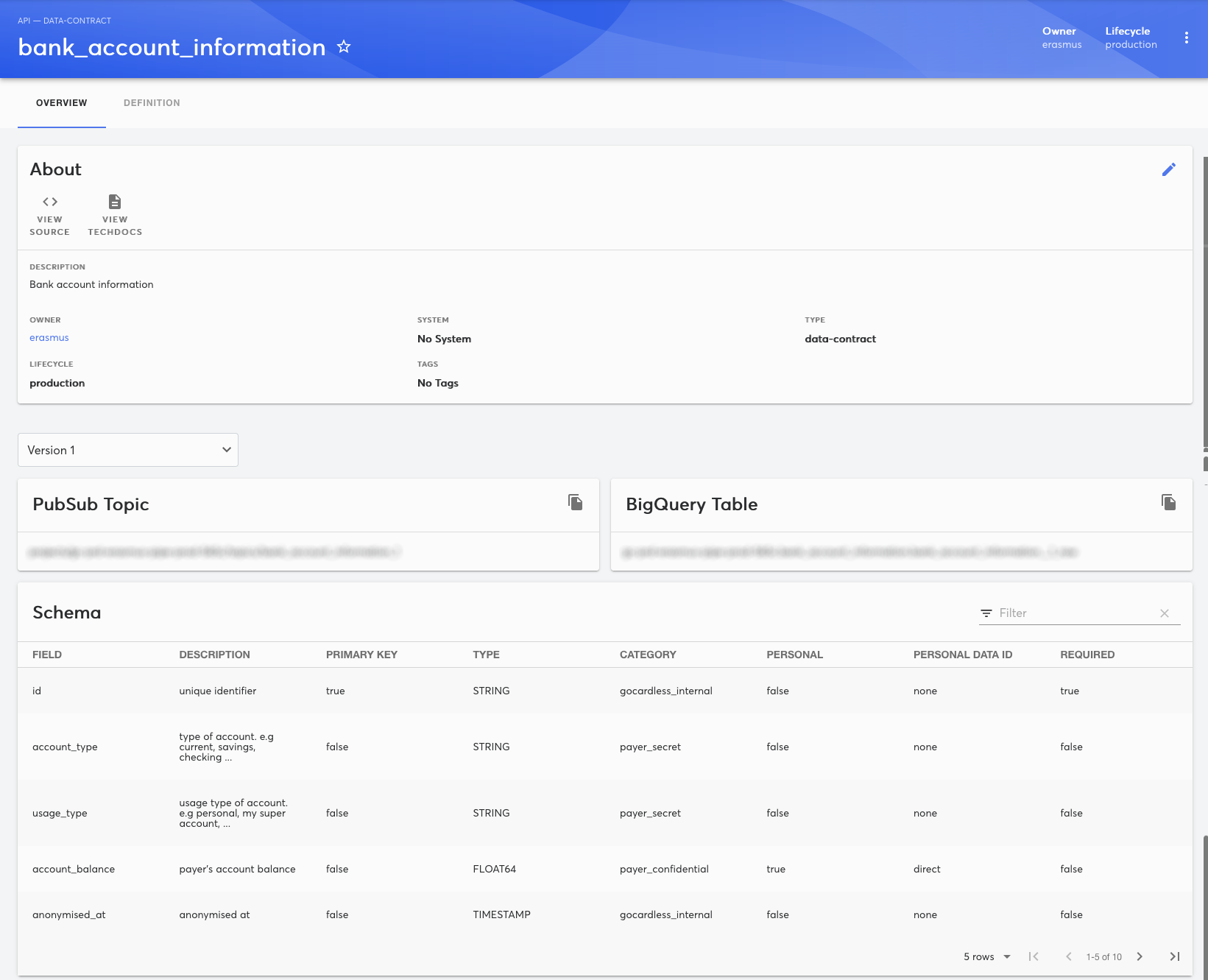
This is what a Data Contract looks like at GoCardless:
{
contract: new() {
metadata+: {
name: 'bank_account_information',
description: 'Information on bank accounts used for ...',
},
schema+: {
versions: [
new_version(
'1',
anonymisation_strategy.overwrite,
[
field(
'bank_account_id',
'Unique identifier for a specific bank account, following the standard GC ID format.',
data_types.string,
field_category.gocardless_internal,
is_personal_data.yes,
personal_data_identifier.indirect,
field_anonymisation_strategy.none,
required=true,
primary_key=true,
),
field(
'account_balance',
'Payer\'s account balance. May be positive or negative.',
data_types.double,
field_category.payer_confidential,
is_personal_data.yes,
personal_data_identifier.direct,
field_anonymisation_strategy.nilable
),
field(
'account_holder_name',
'Payer\'s account holder name, as entered by the payer.',
data_types.string,
field_category.payer_confidential,
is_personal_data.yes,
personal_data_identifier.direct,
field_anonymisation_strategy.hex
),
],
[ ddrSubject('bank_accounts', "bank_account_id"), ],
) + withPubSub() + withBigQuery(),
],
},
},
}
And that’s all there is! It’s defined in Jsonnet, which is a configuration language that can be evaluated to JSON, YAML, and other formats, as that’s what we use throughout Utopia, as well as being fully customisable to our specific needs at GoCardless.
Deploying the Data Contract
Once the Data Contract definition is merged to a Git repository by the data owners themselves, we create the following resources, services, and deployments.
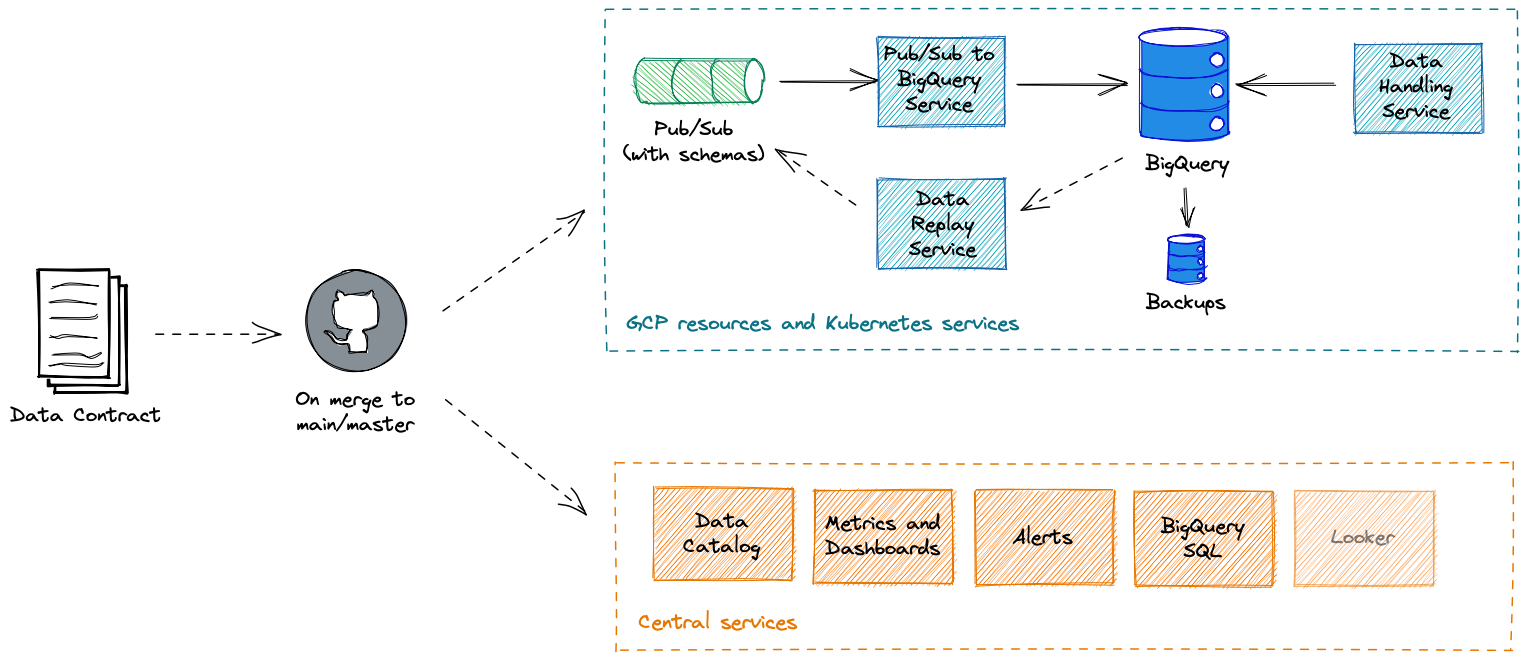
All of this is done on behalf of the data owners. The GCP resources and Kubernetes services are per-Data Contract, so something that affects one pipeline will not affect another.
The GCP resources are within their own services GCP projects, explicitly giving the data owners the autonomy to manage them and the responsibility to do so. Alerts from the Kubernetes services are routed to the data owners, as typically they will be best placed to handle them. If not, the Data Infrastructure team is always there for second-line support.
Our implementation of Data Contracts is designed to be flexible. We don’t care how the data is structured, so long as it has all the information we need to build and deploy the services and resources used to manage that data. We allow users to choose what services they need, and we’ve found that nearly a third of users have chosen not to deploy Pub/Sub, and many choose not to create a BigQuery table, which makes it a good fit for inter-service communication use cases. This all is part of how we promote the autonomy of our data generators.
We also use the contract and the metadata within it to update centralised services, for example our data catalog. Moreover, because we’re using tools like BigQuery and Looker, although the data is segregated in order to promote ownership and autonomy, it’s not silo’d - you can query data from different GCP projects without any cost or limitations, allowing consumers to join data sets and find insights no matter who owns and manages the underlying data.
It’s not all about the implementation
This implementation is obviously very specific to us. We happen to have an excellent infrastructure platform we can build on that was a perfect fit for what we want to achieve with Data Contracts. It has allowed us to build what we refer to as our contract-driven data infrastructure, where from a Data Contract we can deploy all the tooling and services required to generate, manage and consume that data.
But the implementation isn’t the most important part. As Tristan Handy wrote recently, what matters is the “identification of the problem and alignment on the types of guarantees we need our systems to provide us”.
Ultimately we see Data Contracts as our vessel for improving data quality at GoCardless. We’re changing the data culture at the organisation, supported by our best-in-class data infrastructure, and guaranteed by a Data Contract.